| Sleepy.md
Datong, en la provincia de Shanxi, una ciudad que en el pasado sustentaba la mitad del país con el carbón, hoy se sacude todo el polvo de carbón de encima, cambia el pesado cincel por uno más afilado y golpea con fuerza hacia otra mina invisible.
En los edificios de oficinas del centro internacional Jinmao, en el distrito Pingcheng, ya no hay pozos de ascenso y descenso para el transporte. Tampoco hay camiones para llevar carbón. En su lugar, hay miles de puestos de ordenador estrechamente dispuestos. La base de datos inteligentes “Shanghai Runxun Yunzhong Shenggu” ocupa varias plantas completas; miles de jóvenes empleados con auriculares están mirando las pantallas, haciendo clic, arrastrando y seleccionando con un cuadro.
Según datos oficiales, para noviembre de 2025, la ciudad de Datong ya tiene 745k servidores en funcionamiento; ha incorporado 69 empresas de etiquetado y anotación de datos de centros de llamadas, lo que impulsa más de 30k oportunidades de empleo cercano; el valor de la producción alcanza 750 millones de yuanes. En este pozo minero de números, el 94% de los trabajadores tiene registro local.
No solo es Datong. Entre las primeras bases de anotación de datos determinadas por la Oficina Nacional de Datos, aparecen de forma destacada condados del interior de Shanxi Yonghe, Bijie en Guizhou, Mengzi en Yunnan y otros. En la base de anotación de datos de Yonghe, el 80% son empleadas. La mayoría son madres campesinas, o jóvenes que regresaron a su lugar de origen porque no encontraron un trabajo adecuado.
Hace cien años, en una fábrica textil de Manchester, en Reino Unido, se amontonaban agricultores que habían perdido sus tierras. Y hoy, frente a las pantallas de ordenador en estos condados remotos, hay jóvenes que no encuentran su sitio en la economía real.
Están realizando un trabajo a destajo con una estética muy futurista, pero extremadamente primitiva, que produce para gigantes de la inteligencia artificial en Beijing, Shenzhen y Silicon Valley los datos necesarios para sus grandes modelos.
Nadie considera que haya nada de malo.
Nueva línea de producción en la meseta de Loess
La esencia del etiquetado de datos es enseñar a las máquinas a reconocer el mundo.
La conducción autónoma necesita identificar semáforos y peatones; los grandes modelos necesitan distinguir qué es un gato y qué es un perro. La máquina, en sí, no tiene sentido común; es necesario que los humanos dibujen primero un cuadro en una imagen, diciéndole “esto es un peatón”, y solo entonces, tras haberse tragado millones de imágenes, aprende a identificarlas por sí misma.
Este trabajo no requiere un nivel académico alto; solo paciencia, y un dedo índice capaz de hacer clic sin detenerse.
En la época dorada de 2017, un simple cuadro 2D podía costar más de un centavo de yuan (una décima de yuan), incluso había empresas que ofrecían precios de 0,5 de yuan. Los etiquetadores con manos rápidas, trabajando día tras día durante dieciséis horas, podían ganar entre 500 y 600 yuanes. En un condado, esto se considera absolutamente un trabajo bien pagado y digno.
Pero con la evolución de los grandes modelos, la cara cruel de esta línea de producción empieza a salir a la luz.
En 2023, el precio unitario del etiquetado simple de imágenes ya se había derrumbado hasta 0,03 a 0,04 yuanes (3 a 4 fen). La caída superó el 90%. Incluso en las imágenes de nubes de puntos 3D, con mayor dificultad: esas imágenes formadas por puntos densos, que requieren ampliarse innumerables veces para ver los bordes con claridad, los etiquetadores también deben trazar en el espacio tridimensional un cuadro sólido que incluya largo, ancho, alto y el ángulo de desviación, para envolver de forma precisa el vehículo o el peatón; y aun así, ese complejo cuadro 3D solo tiene 5 fen de pago.
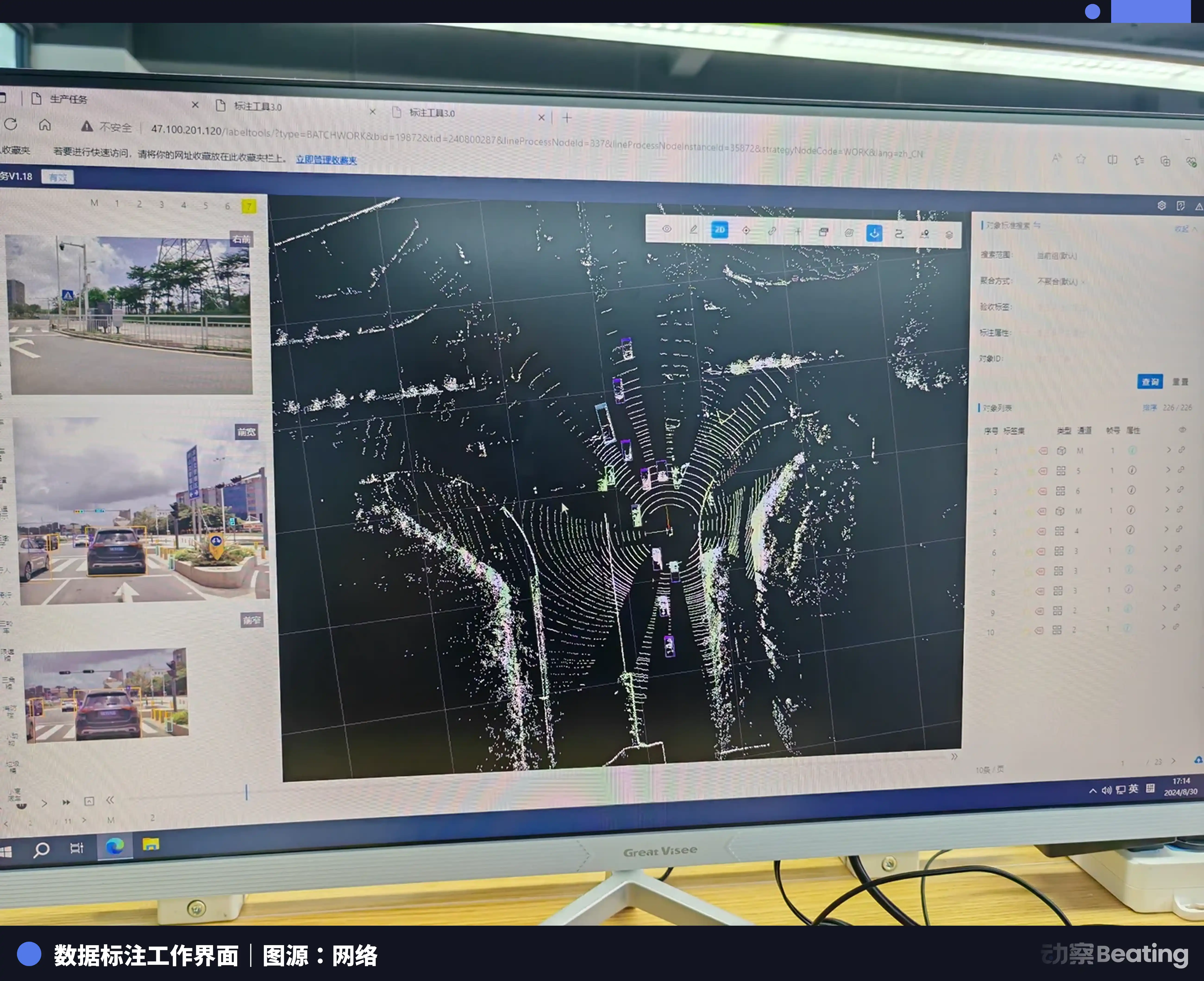
La consecuencia directa de la caída vertiginosa del precio unitario es el aumento brutal de la intensidad laboral. Para apretar y no soltar los 2.000 o 3.000 yuanes al mes de salario base, los etiquetadores tienen que aumentar constantemente, sin parar, su velocidad de mano.
Esto no es en absoluto un trabajo ligero de oficina. En muchas bases de etiquetado, la gestión es tan estricta que asfixia: está prohibido atender llamadas durante el trabajo y el móvil debe quedar bloqueado en el compartimento de almacenamiento. El sistema registra con precisión la trayectoria del mouse de cada empleado y el tiempo de permanencia; si se detienen más de tres minutos, las advertencias del sistema llegan como un látigo.
Lo que además desespera es la tasa de tolerancia al error. En la industria, el umbral de aprobado suele estar por encima del 95%; algunas empresas incluso exigen 98%-99%. Esto significa que, si trazas 100 cuadros y te equivocas en 2, toda la imagen se devuelve para corregir y rehacer.
Las imágenes dinámicas van encadenadas cuadro a cuadro: cuando un vehículo cambia de carril queda oculto, y el etiquetador debe buscarlos uno por uno por inferencia; en nubes de puntos 3D, basta con que un objeto tenga más de 10 puntos para que haya que dibujar un cuadro. En un proyecto complejo de plazas de estacionamiento, si las líneas son largas o se omiten etiquetas, durante la inspección de calidad siempre pueden sacar fallos. Rehacer una imagen cuatro o cinco veces es cosa común. Al final, tras sumar todo el tiempo, con una hora de trabajo lo que llega a la mano son solo unas cuantas décimas.
Una etiquetadora de Hunan publicó su hoja de liquidación en una plataforma social. Tras un día de trabajo, había trazado más de 700 cuadros; el precio unitario era de 4 fen; su ingreso total fue de 30,2 yuanes.
Es una escena extremadamente contradictoria.
Por un lado, hay grandes directivos tecnológicos impecables en el escenario que hablan de cómo la AGI liberará a la humanidad; por el otro, en los condados de la meseta de Loess y de las montañas del suroeste, los jóvenes pasan cada día 8 a 10 horas mirando fijamente la pantalla, dibujando cuadros de manera mecánica, miles, decenas de miles, e incluso por la noche sueñan, con los dedos dibujando líneas de carril en el aire.
Alguien dijo alguna vez que la apariencia de la inteligencia artificial es como un coche de lujo que pasa rugiendo, pero al abrir la puerta descubres que dentro hay cien personas que van en bicicleta, mordiéndose los dientes y pisando los pedales con todas sus fuerzas.
Nadie considera que haya nada de malo.
Trabajo a destajo para enseñar a las máquinas “cómo amar”
Cuando se rompe el cuello de botella del reconocimiento de imágenes, los grandes modelos entran en una evolución más profunda. Ahora necesitan aprender a pensar, conversar e incluso mostrar “empatía” como los humanos.
Esto da lugar al eslabón más central y también más costoso del entrenamiento de grandes modelos: RLHF (aprendizaje por refuerzo a partir de retroalimentación humana).
Dicho de forma sencilla: se hace que personas reales califiquen las respuestas generadas por la IA, diciéndole qué respuesta es mejor y cuál se ajusta más a los valores humanos y preferencias emocionales.
ChatGPT parece “humano” precisamente porque detrás hay un sinfín de etiquetadores RLHF que le están dando clases.
En plataformas de crowdsourcing, estas tareas de etiquetado suelen estar cotizadas con un precio claro: 3 a 7 yuanes por pieza. Los etiquetadores deben calificar con una valoración emocional extremadamente subjetiva las respuestas de la IA, para decidir si esa respuesta es “cálida”, si “tiene empatía” y si “se ha preocupado por las emociones del usuario”.
Una persona de base con un salario de 2.000 o 3.000 yuanes al mes, que en el barro de la vida real no puede parar de correr y además ni siquiera tiene tiempo de ocuparse de sus propias emociones, tiene que actuar como mentor emocional y juez de valores para la IA dentro del sistema.
Necesitan triturar a la fuerza sentimientos humanos extremadamente complejos y sutiles como la calidez y la empatía, y cuantificarlos en fríos puntajes de 1 a 5. Si sus calificaciones no coinciden con el “modelo correcto” configurado por el sistema, se considerará que no cumplen el estándar de precisión, y se les recortará el salario a destajo, que ya era escaso.
Es una especie de vacío cognitivo. Las complejas emociones humanas, la moral y la compasión se están arrastrando a la fuerza dentro de un embudo algorítmico. En las escalas frías de cuantificación y estandarización, se les exprime el último rastro de calor. Cuando te sorprende que el monstruo cibernético de la pantalla ya aprendió a escribir poemas, a componer música, y también a preocuparse preguntando por el bienestar; fuera de la pantalla, esa gente humana, que antes era viva, en el juicio mecánico día tras día se degrada hasta convertirse en una máquina de calificar sin emociones.
Esta es la cara más secreta de toda la cadena de la industria: nunca aparece en noticias de financiación ni en boletines técnicos de ningún tipo.
Nadie considera que haya nada de malo.
Licenciados de maestría 985 y jóvenes de pueblos
El trabajo de tirar cuadros de base está siendo aplastado por las orugas de la IA; esta línea de producción cibernética empieza a extenderse hacia arriba y a devorar trabajo intelectual de nivel superior.
El apetito de los grandes modelos cambió. Ya no se conforma con triturar el sentido común simple: necesita tragarse el conocimiento profesional humano y la lógica de alto nivel.
En las plataformas de contratación grandes empiezan a aparecer con frecuencia este tipo de trabajos de medio tiempo especiales, como “etiquetado de razonamiento lógico para grandes modelos” o “entrenador de humanidades de IA”. El umbral para esta ocupación es muy alto: a menudo exige “título de maestría 985/211 o superior”, e implica áreas profesionales como derecho, medicina, filosofía y literatura.
Muchos estudiantes de posgrado de escuelas prestigiosas fueron atraídos y se metieron en estos grupos de subcontratación de grandes empresas. Pero pronto descubrieron que no se trataba de ningún ejercicio intelectual ligero, sino de un tormento mental.
Antes de aceptar pedidos oficiales, deben leer documentos de decenas de páginas sobre dimensiones de calificación y criterios de evaluación, y realizar dos o tres rondas de prueba de etiquetado. Tras cumplir, durante el etiquetado oficial, si la precisión queda por debajo del nivel promedio, pierden la elegibilidad y son expulsados del grupo de chat.
Lo más asfixiante es que estos criterios ni siquiera son fijos. Ante problemas y respuestas similares, si los evalúas con la misma forma de pensar, el resultado puede ser completamente opuesto. Es como hacer un examen que nunca se acaba y que, además, no tiene respuestas estándar. No se puede mejorar la precisión con el esfuerzo o el estudio en el propio lugar: solo se sigue dando vueltas en círculo, consumiendo mente y cuerpo.
Ese es el nuevo tipo de explotación en la era de los grandes modelos: el colapso de clases.
El conocimiento, que alguna vez fue visto como la escalera de oro para romper barreras y trepar hacia arriba, ahora se ha convertido en forraje numérico, cada vez más complejo de masticar, que se ofrece y consagra para los algoritmos. Ante el poder absoluto de los algoritmos y los sistemas, la maestría 985 de la torre de marfil y el joven de un pueblo en la meseta de Loess llegan a un destino extrañamente idéntico por caminos distintos.
Caen juntos dentro de este pozo cibernético sin fondo, les arrebatan el brillo, nivelan las diferencias y se convierten todos en engranajes baratos sobre la cinta, que pueden reemplazarse en cualquier momento.
En el extranjero es igual. En 2024, la empresa Apple eliminó directamente un equipo de etiquetado de voz de IA de 121 personas en Santiago. Esos empleados se encargaban de mejorar la capacidad de Siri para manejar múltiples idiomas. Ellos creían que estaban en el borde del negocio central de las grandes empresas, pero en un instante cayeron en el abismo profundo del desempleo.
Para los gigantes tecnológicos, tanto las “señoras” que tiran cuadros en un condado como los entrenadores de razonamiento que se graduaron de una escuela prestigiosa, en esencia son “consumibles” que se pueden reemplazar en cualquier momento.
Nadie considera que haya nada de malo.
Un Babel de billones, sudor y sangre construidos con unos cuantos fen
Según los datos publicados por el China Academy of Information and Communications Technology (CAICT), el tamaño del mercado de etiquetado de datos en China en 2023 fue de 6.080 millones de yuanes; en 2025 se prevé 20.000 a 30.000 millones. Según las proyecciones, para 2030, las ventas del mercado global de etiquetado de datos y servicios aumentarán en picada hasta 117.100 millones de yuanes.
Detrás de estas cifras está la fiesta de valoraciones, sin parar, de gigantes tecnológicos como OpenAI, Microsoft, ByteDance, etc., que van fácilmente de cientos de miles de millones a varios billones de dólares.
Pero esa lluvia de riqueza no fue a parar a las personas que realmente “alimentan” a la IA.
La industria china de etiquetado de datos presenta una estructura típica de subcontratación con forma de pirámide invertida. En la capa superior están los gigantes tecnológicos que sujetan con fuerza los algoritmos centrales. En la segunda capa están los grandes proveedores de servicios de datos. En la tercera capa están las bases de etiquetado de datos repartidas por todas partes y las empresas subcontratistas medianas y pequeñas. Solo en la capa más baja están esos etiquetadores de “gente de campo” que cobran salario a destajo.
Cada nivel de subcontratación se lleva con fuerza su propio bocado de “grasa”. Cuando el gran fabricante fija el precio unitario en 5 mao, tras pasar por capas de extracción, el que llega al etiquetador del condado quizá ni siquiera sea 5 fen.
El ex ministro de Finanzas griego Yanis Varoufakis, en su libro “Technological Feudalism”, planteó una visión extremadamente penetrante: hoy los gigantes tecnológicos ya no son capitalistas en el sentido tradicional, sino “cloudalists” (“señores del la nube”).
No poseen fábricas y máquinas, sino algoritmos, plataformas y potencia de cómputo; todo esto son territorios digitales en la era cibernética. En este nuevo sistema feudal, los usuarios no son consumidores, sino aparceros digitales: cada “me gusta”, comentario o visualización en nuestras redes sociales está suministrando datos gratis a los señores del la nube.
Y los etiquetadores de datos que están repartidos en los mercados de demanda inferior son, en este sistema, los esclavos digitales de base. No solo tienen que producir datos, sino también limpiar, clasificar y puntuar una ingente cantidad de datos primarios para convertirlos en forraje de alta calidad que los grandes modelos puedan digerir.
Es una campaña secreta de acaparamiento cognitivo. Igual que el movimiento de cercamientos del siglo XIX en Reino Unido empujó a los campesinos hacia las fábricas textiles, hoy la ola de IA empuja a esos jóvenes que no encuentran un lugar en la economía real hacia delante de las pantallas.
La IA no ha borrado la brecha entre clases; al contrario, ha construido una “cinta transportadora de datos y sudor” que va desde los condados del centro y oeste de China hasta las sedes de los gigantes tecnológicos en Beijing, Tianjin, Shanghai, Guangzhou y Shenzhen. La narrativa de la revolución tecnológica siempre es grandiosa y deslumbrante, pero su color de fondo será, para siempre, el consumo a gran escala de mano de obra barata.
Nadie considera que haya nada de malo.
Ya no se necesita el mañana de los humanos
El final más cruel ya está por llegar, cada vez más rápido.
A medida que mejora la capacidad de los grandes modelos, esas tareas de etiquetado que antes requerían que humanos trabajaran día y noche, están siendo tomadas por la IA.
En abril de 2023, el fundador de Ideal Auto, Li Xiang, reveló datos en un foro: antes, Ideal tenía que hacer aproximadamente 10 millones de fotogramas de anotación manual de imágenes para conducción autónoma al año; el costo de subcontratar era cercano a un billón. Pero cuando utilizaron grandes modelos para la anotación automatizada, lo que antes requería un año, básicamente se completaba en solo 3 horas.
La eficiencia es 1000 veces la de una persona, y además fue desde 2023. En el mes de marzo recién pasado, Ideal también publicó el nuevo motor de anotación automática MindVLA-o1 de nueva generación.
En la industria circula una broma extremadamente real: “Cuánta inteligencia hay, tanta mano de obra hay”. Pero ahora, en lo que respecta a la inversión de los grandes fabricantes en subcontratar etiquetado de datos, ya apareció una caída pronunciada del 40%-50%.
Aquellos jóvenes de pueblo que se quedaron miles de noches frente a un ordenador, y a fuerza de desvelarse tenían los ojos rojos, alimentaron a una bestia gigante a mano. Y ahora, esta bestia le da vuelta a la cara y les destroza el pan: les rompe el trabajo que les sostenía.
Al caer la noche, los edificios de oficinas en el distrito Pingcheng de Datong siguen pálidos como el día. Los jóvenes que cambian de turno se intercambian en silencio sus cuerpos cansados dentro del pasillo del ascensor. En este espacio plegado en el que incontables cuadros poligonales encierran con fuerza, nadie se preocupa por qué clase de salto épico acaba de tener la arquitectura Transformer del otro lado del océano, ni nadie entiende el estruendo de la potencia de cómputo detrás de cientos de miles de millones de parámetros.
Su mirada solo queda soldada en esa barra de progreso roja y verde que representa el “umbral de aprobado”, calculando si esos puntos, décimas y fen de pago a destajo se pueden juntar para vivir una vida digna a fin de mes.
Por un lado, el tañido de la campana en el Nasdaq y las incontables columnas de los medios tecnológicos; los gigantes brindan por la llegada de la AGI. Por el otro, esos esclavos digitales que alimentaron a la IA a pulso, a bocado tras bocado con carne y hueso, solo pueden esperar con miedo en sueños doloridos y cansados, a que esa bestia que ellos mismos criaron, en alguna mañana aparentemente normal, pateé sin emoción su mesa de trabajo fuera de su alcance.
Nadie considera que haya nada de malo.
Haz clic para conocer vacantes de Lvydong BlockBeats
Bienvenido a unirte a la comunidad oficial de Lvydong BlockBeats:
Grupo de suscripción Telegram: https://t.me/theblockbeats
Grupo de chat Telegram: https://t.me/BlockBeats_App
Cuenta oficial de Twitter: https://twitter.com/BlockBeatsAsia

