| Sleepy.md
У місті Датун (провінція Шаньсі), яке колись живилося вугіллям і тримало половину країни на своїх плечах, нині струшує з себе весь вугільний пил, бере гострий кайло й важко б’є по іншому, невидимому копальні.
У офісних будівлях Центру міжнародної торгівлі «Цзіньмао» у районі Пінченчуй більше немає підйомних шахт. Немає і вантажівок для перевезення вугілля. Натомість — тисячі комп’ютерних робочих місць, щільно розставлених у ряд. «База великих даних розумних сервісів Юньчжун Шанхай Жунсюнь» займає цілі кілька поверхів: тисячі молодих співробітників у навушниках пильно дивляться на екрани, натискають, перетягують, обводять рамками.
Згідно з офіційними даними, станом на листопад 2025 року в Датуні запущено 745 тис. серверів, залучено 69 компаній з call-кол- та размітки (маркування) даних, що дало змогу працевлаштувати на місці понад 30 тис. людей; додана вартість — 750 млн юанів. У цьому «цифровому кар’єрі» 94% працівників — місцеві жителі за реєстрацією домогосподарства.
Це не лише Датун. У переліку перших баз для маркування даних, визначеному Державною адміністрацією з даних, серед північно- та південно-західних повітів виразно фігурують Юнхе повіту Юнхе (Шаньсі), Цзачіє — повіт Біє (Гуйчжоу), Мунцзи — повіт Монцзи (Юньнань) тощо. У базі маркування даних у повіті Юнхе 80% працівників — жінки. Переважно це сільські мами, або молодь, що повернулася додому, бо не змогла знайти підходящу роботу.
Сто років тому на текстильній фабриці в Манчестері, Англія, було повно селян, позбавлених землі. А сьогодні перед екранами комп’ютерів у цих віддалених повітових містечках сидять молоді люди, яким не знайшлося місця в реальному секторі економіки.
Вони виконують роботу заштатну за кількістю, водночас глибоко «майбутню» за формою, але вкрай примітивну за суттю, — виробляють для ІТ-гігантів з Пекіна, Шеньчженя та Силіконової долини, яким потрібні великі моделі, необхідний «корм» із даних.
Ніхто не вважає, що в цьому є проблема.
Нова конвеєрна лінія на Лесовому плато
Суть маркування даних — навчити машину розпізнавати світ.
Для автоматичного водіння потрібно вміти розпізнавати світлофор і пішоходів, а для великої моделі — відрізняти, що є кіт, а що собака. У самої машини немає здорового глузду: її має навчити людина — спершу намалювати на зображенні рамку й сказати: «Ось пішохід». Лише після цього, «пожувавши» мільйони зображень, вона зможе навчитися впізнавати сама.
Цій роботі не потрібна висока освіта — лише терпіння і один палець, який може безперервно натискати.
У 2017 році, в «золоту добу», проста 2D-рамка могла коштувати понад десяту частину юаня; навіть траплялися компанії, які пропонували п’ять десятих (0,5 юаня) за високу ціну. Оператори з швидкою рукою могли працювати по дванадцять годин на добу й заробляти п’ять-шість сотень юанів. У повітових містечках це точно вважалося високою зарплатою та пристойною роботою.
Але з еволюцією великих моделей жорстокий бік цієї лінії почав проявлятися.
У 2023 році одинична ціна простого маркування зображень уже впала до 3–4 фень (десятих часток). Падіння перевищило 90%. Навіть для складніших 3D- хмар точок, де зображення складене з щільних точок і щоб розгледіти краї, потрібно збільшити зображення в тисячі разів, маркувальникам усе одно доводилося у тривимірному просторі «витягувати» об’ємну рамку, що охоплює довжину, ширину, висоту та кут відхилення, щільно огортаючи автомобіль чи пішохода. І навіть така складна 3D-рамка мала лише 5 фень.
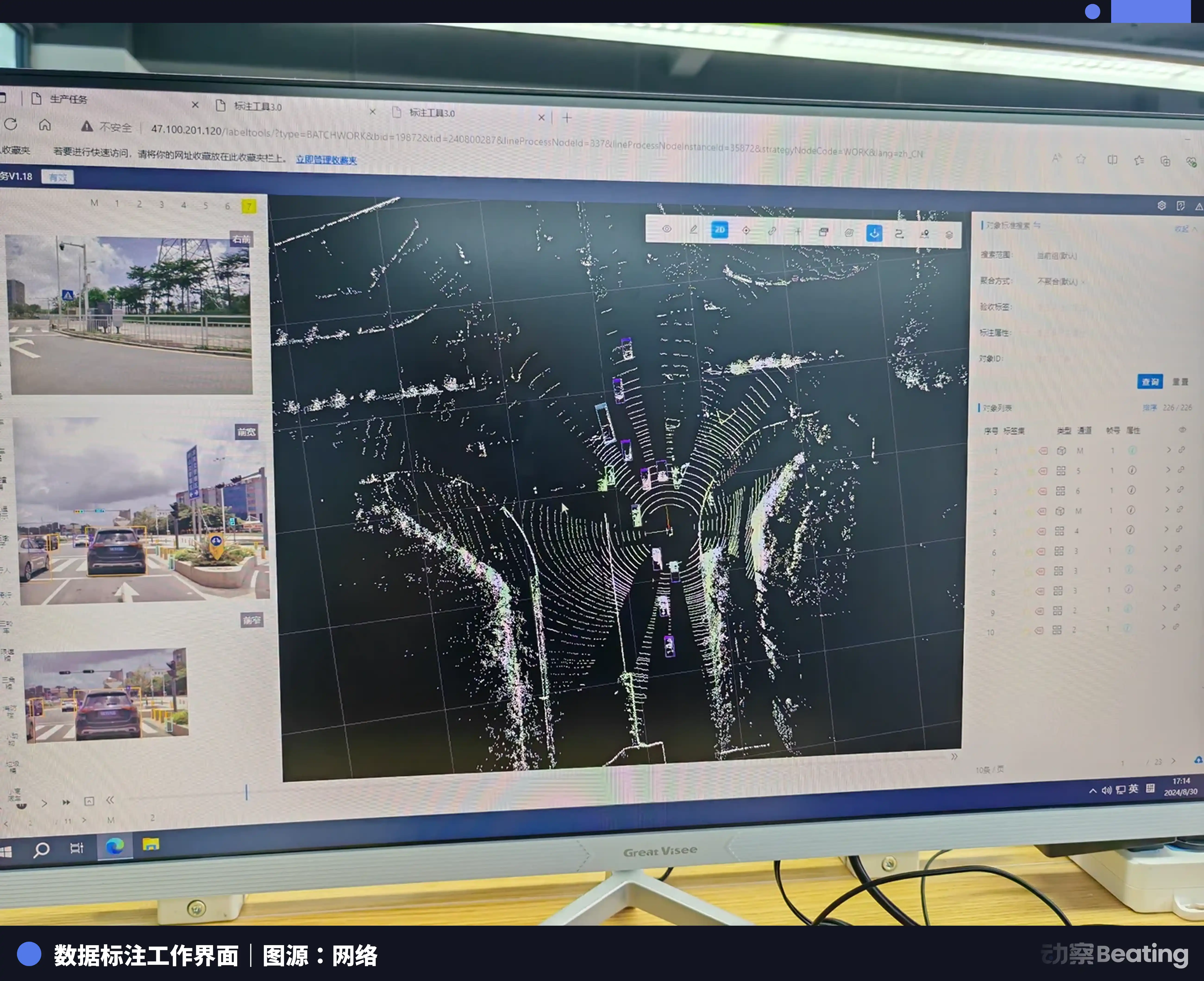
Безпосередній наслідок обвалу ціни — різке зростання трудового навантаження. Щоб міцно втриматися за щомісячний базовий оклад у 2–3 тис. юанів, маркувальники змушені постійно, безупинно підвищувати швидкість роботи пальцями.
Це взагалі не «легка офісна» робота. У багатьох базах маркування управління настільки суворе, що аж душить: на робочому місці заборонено відповідати на дзвінки, а мобільний телефон має бути заблокований у шухляді для зберігання речей. Система точно фіксує траєкторію миші кожного працівника та час перебування: якщо зупинитися більш ніж на три хвилини, попередження з бекенду прилітає, наче батіг.
Ще далі збиває з ніг показник допустимої помилки. Зазвичай прохідний рівень у галузі — понад 95%; інколи компанії вимагають 98%–99%. Це означає: ви обводите 100 рамок — якщо ви помилилися лише у двох, усе зображення повернуть на переробку.
Динамічне зображення — це кадри, пов’язані між собою: при зміні смуги автомобіль може бути частково перекритий, і маркувальнику доводиться витягувати їх по одному через асоціації. У 3D-хмарі точок: якщо об’єктів більше ніж 10 точок — потрібно малювати рамку. Під час проєкту зі складною парковкою, якщо лінія тягнеться довго і щось пропущено, на технічному контролі все одно знайдуть ваду. Переробка одного зображення чотири-п’ять разів — буденна справа. Врешті-решт виходить так, що витрачаєте годину — а на руки отримуєте лише кілька фень.
Одна з маркувальниць у Хунані на платформі соціальних мереж показала свій розрахунковий лист: за день вона зробила понад 700 рамок, одинична ціна — 4 фень, загальний дохід — 30,2 юаня.
Це надзвичайно розірвана картина.
З одного боку — на презентаціях блискучі та привабливі технічні «світилa», що говорять про те, як AGI звільнить людей; з іншого — у повітових містечках на Лесовому плато й у горах Південного Заходу молодь щодня 8–10 годин «мертво» дивиться в екран, механічно тягне рамки — тисячі, десятки тисяч, і навіть уночі в снах пальці в пів-небі прокреслюють лінії доріг.
Колись хтось казав: зовнішність штучного інтелекту — наче розкішний суперкар, що мчить повз, але, відкривши двері, ви бачите, що всередині сотня людей їздить на велосипеді й зціпивши зуби з усіх сил крутить педалі.
Ніхто не вважає, що в цьому є проблема.
Поштова робота за кількістю, що вчить машини «як любити»
Коли вузьке місце розпізнавання зображень було «пробите», великі моделі отримали ще глибшу еволюцію: їм треба навчитися мислити, вести розмову — і навіть демонструвати «співпереживання», як люди.
Це породило найключовіший і найдорожчий етап у навчанні великих моделей — RLHF (reinforcement learning from human feedback, підкріплене навчання на основі людського зворотного зв’язку).
Якщо просто, це означає: нехай реальні люди оцінюють відповіді, згенеровані AI, і підкажуть, яка відповідь краща та більше відповідає цінностям і емоційним вподобанням людини.
Те, що ChatGPT виглядає «ніби людина», пояснюється тим, що за лаштунками безліч RLHF-маркувальників «вчить» його.
На краудсорсингових платформах такі завдання часто мають чітко встановлену ціну: за одиницю 3–7 юанів. Маркувальники мають надзвичайно суб’єктивно оцінювати емоції відповідей AI, визначаючи, чи «тепла» ця відповідь, чи в ній «є емпатія», чи «враховано емоції користувача».
Людина, яка отримує зарплату 2–3 тис. юанів на місяць, знемагає в реальних брудних буднях і навіть не встигає дбати про власні емоції, у системі має бути емоційним наставником AI та суддею цінностей.
Їм треба силоміць розтерти на дрібні шматочки такі неймовірно складні й тонкі людські почуття, як «тепло» і «емпатія», а потім кількісно перетворити їх на холодні бали від 1 до 5. Якщо їхні оцінки не збігаються із «правильними еталонами», заданими системою, їх визнають такими, що не досягли потрібної точності, і тоді зменшать винагороду за штучну роботу — і без того мізерну.
Це видалення здібностей пізнання. Складні й делікатні людські емоції, мораль і співчуття силоміць втягують у алгоритмічну вирву. На холодних шкалах кількісної оцінки та стандартизації їх «вичавлюють» до останньої краплі тепла. Коли ви дивуєтеся, що на екрані кіберчудовисько вже навчилося писати вірші та музику, турботливо з’ясовує, як справи, і навіть одягає на себе маску сентиментальності; з іншого боку, за екраном ті самі живі люди — щодень у механічних судженнях деградують до беземоційних машин для виставлення балів.
Це найтаємніша сторона всієї виробничої ланки — вона ніколи не з’являється ні в жодних новинах про фінансування, ні в технічних білих книгах.
Ніхто не вважає, що в цьому є проблема.
985 магістри й молодь із містечок
Робота з «натягування рамок» на нижньому рівні розчавлюється гусеницями AI. Ця кібер-конвеєрна лінія починає поширюватися вгору, поглинаючи більш високорівневу інтелектуальну працю.
Апетит великих моделей змінився. Тепер вони не задовольняються тим, що пережовують прості міркування здорового глузду; їм потрібно «поїдати» людські професійні знання та логіку вищого порядку.
На великих платформах вакансій починають часто спалахувати певного роду спеціальні підробітки, наприклад: «маркування логічного міркування для великої моделі», «AI-тренер із гуманітарних дисциплін». Поріг для такої підробітки дуже високий: часто потрібно мати «диплом 985/211 магістра або вище», і це стосується таких сфер, як право, медицина, філософія, література тощо.
Багато аспірантів з провідних вузів приваблюються й вливаються в ці зовнішні (аутсорсингові) групи великих компаній. Але дуже швидко вони розуміють: це не просто легка інтелектуальна гімнастика, а психічні муки.
Перед тим як офіційно брати замовлення, їм потрібно прочитати документи на десятки сторінок із вимірами для оцінювання та критеріями, пройти дві-три пробні оцінки (пробне маркування). Після проходження, під час офіційного маркування, якщо точність нижча за середній рівень, їм одразу відмовляють у доступі та виключають із чату.
Найбільш задушливе те, що ці стандарти взагалі не є фіксованими. Коли стикаєшся зі схожими питаннями й відповідями, якщо оцінювати за однією й тією ж манерою мислення, результат може виявитися цілком протилежним. Це ніби робиш тест, який ніколи не закінчується і в якому немає жодної еталонної відповіді. Немає змоги підвищити точність самовдосконаленням чи навчанням — можна лише безперервно крутитися на місці, витрачаючи мозок і сили.
Ось це і є нова експлуатація в епоху великих моделей — «схлопування класів».
Знання — ця колись золота сходинка, яку вважали способом прорвати стіни та підійматися вгору, — нині перетворили на цифровий «корм», який потрібно підносити алгоритму, і який ще складніше пережовувати. Під абсолютною владою алгоритмів і систем 985 магістри з академічної «вежі зі слонової кістки» й молодь із містечок на Лесовому плато прийшли до найдивнішого збігу різних шляхів.
Усі разом вони падають у цю бездонну кібер-копальню, втрачають свій «ореол», стирають відмінності й перетворюються на шестерні на гусеницях — дешеві й такі, що їх можна будь-коли замінити.
За кордоном теж так само. У 2024 році компанія Apple прямо звільнила команду з 121 співробітника в Сантьяго, що займалася AI-розміткою/маркуванням голосу. Ці працівники відповідали за покращення здатності Siri обробляти багатомовність. Вони думали, що стоять на периферії основного бізнесу великих компаній, та раптом опинилися в безодні безробіття.
Для технологічних гігантів незалежно від того, це «мама» з маркування рамок у повітовому містечку чи логічний тренер, який закінчив елітний вуз — по суті, усі вони «витратні матеріали», які можна замінити будь-якої миті.
Ніхто не вважає, що в цьому є проблема.
Трильйонна Вавилонська вежа, наповнена пот кров’ю за копійки
Згідно з даними, опублікованими Китаєм Інститутом зв’язку та інформаційних технологій (China Academy of Information and Communications Technology), у 2023 році ринок маркування даних у Китаї сягнув 745k юанів; у 2025 році прогнозують 200–30k юанів. За прогнозом, до 2030 року світові продажі ринку маркування та сервісів для даних злетять до 117,1 млрд юанів.
За всіма цими цифрами стоїть бенкет оцінок (valuation) технологічних гігантів на кшталт OpenAI, Microsoft, ByteDance тощо: вони легко оперують сумами в сотні мільярдів і навіть трильйони доларів.
Але ці багатства, мов «ливень із небес», не дісталися тим людям, які насправді «годують» AI.
Китайська індустрія маркування даних має типовий перевернутий пірамідальний аутсорсинг-ланцюг. На самому верху — технологічні гіганти, які міцно тримають у руках ключові алгоритми. На другому рівні — великі постачальники сервісів із даними. На третьому — бази маркування даних, розкидані по всіх регіонах, та середні/малі аутсорсингові компанії. А внизу — саме ті «селяни-невдахи», які працюють за відрядною оплатою.
Кожен рівень аутсорсингу відтягує собі чималий шматок «олії». Коли одинична ціна, яку скидає великий гравець, становить 0,5 юаня, після багатошарового «обдирання» до маркувальника в повітовому містечку може дійти навіть менше ніж 0,5 юаня.
У книзі «Технологічний феодалізм» колишній міністр фінансів Греції Янніс Варуфакис висунув проникливий погляд: сьогодні технологічні гіганти вже не є капіталістами у традиційному сенсі, а є «хмарними лордами» (Cloudalists).
Вони володіють не фабриками й машинами, а алгоритмами, платформами та обчислювальною потужністю — тобто цифровими територіями епохи кіберпростору. У цій новій феодальній системі користувач — не споживач, а цифровий орендар-данник (цифровий кріпак): кожен наш лайк, коментар і перегляд у соцмережах безкоштовно постачає дані хмарним лордам.
А ті маркувальники даних, розкидані в ринках, що «просідають» (де нижчий рівень розвитку), — це найнижчий рівень цієї системи цифрових «кріпаків». Вони не лише виробляють дані — їм ще треба чистити, класифікувати та оцінювати величезні обсяги сирих даних, перетворюючи їх на високоякісний «корм», який здатні «переварити» великі моделі.
Це прихована кампанія зі «захоплення угідь» через пізнання. Як у XIX столітті рух за «огородження» в Британії загнав селян на текстильні фабрики, так і сьогодні хвиля AI заганяє молодь, якій не знайшлося місця в реальній економіці, на екрани.
AI не згладив прірву між класами; натомість він вибудував «конвеєр даних і поту», що тягнеться від повітових містечок у центральній і західній частинах Китаю прямо до штаб-квартир технологічних гігантів у Пекіні, Шанхаї, Гуанчжоу та Шеньчжені. Наратив технологічних революцій завжди грандіозний і блискучий, але його основа — завжди масштабована «пожираюча» експлуатація дешевої робочої сили.
Ніхто не вважає, що в цьому є проблема.
Більше не потрібне людське «завтра»
Найжорстокіший фінал уже зовсім близько — і настає дедалі швидше.
З підвищенням можливостей великих моделей ті маркувальні завдання, які раніше вимагали від людей безперервної праці вдень і вночі, уже беруть AI під свій контроль.
У квітні 2023 року засновник Ideal Auto Лі Сянь на форумі розкрив дані: раніше, за рік, Ideal треба було виконувати приблизно 10 млн кадрів ручної штучної розмітки/маркування для автоматизованого водіння зображень. Аутсорсингові витрати сягали майже одного мільярда. Але коли вони використали великі моделі для автоматизованого маркування, те, що раніше робили за рік, вони могли завершити приблизно за 3 години.
Ефективність у 1000 разів вища за людську — і це ще в 2023 році. Лише за минулий березень Ideal ще й оголосила про новий MindVLA-o1 автоматичний маркувальний рушій наступного покоління.
У галузі ходить фраза самоприниження, що звучить надзвичайно правдиво: «Скільки є розуму, стільки й людей». Але зараз інвестиції великих компаній в аутсорс маркування даних уже впали на 40%–50% за різким «провалом».
Ті молоді люди з містечок, що по безлічі ночей і днів сиділи перед комп’ютерами й витягали очі до почервоніння, власноруч вигодували одне велетенське чудовисько. А тепер ця потвора обертається й ламає їм робочі хліби.
Коли спускається ніч, офісні будівлі в районі Пінченчуй Датуна все так само біліють, наче вдень. Молодь, яка змінює зміну, безмовно передає одне одному зношені тіла в холах ліфтів. У цьому складеному просторі, де нескінченні багатокутні рамки міцно «замкнули» людей, нікому не цікаво, який саме епохальний стрибок щойно відбувся з архітектурою Transformer на іншому боці океану, і ніхто не може розібратися в гуркоті обчислювальної потужності за сотні мільярдів параметрів.
Їхній погляд заварений на бекенді — на червоній зелено-перемикаючій шкалі «прохідного рівня» — і вони прикидають, чи можна зібрати наприкінці місяця ці крихітні бали й копійчані гроші в пристойне життя.
З одного боку — удари дзвона на NASDAQ і нескінченні публікації технологічних медіа: гіганти піднімають тости на честь приходу AGI; з іншого боку — ті цифрові кріпаки, яких вигодовували AI по одному ковтку власною плоттю, — можуть лише тремтіти й чекати в кислих від болю снах, що та потвора, яку вони самі виростили, одного разу в якийсь звичайний з вигляду ранок легковажно викине їм геть робочі хліби.
Ніхто не вважає, що в цьому є проблема.
Натисніть, щоб дізнатися про набір на посади в律動BlockBeats
Ласкаво просимо приєднатися до офіційної спільноти 律動 BlockBeats:
Telegram підписка групи: https://t.me/theblockbeats
Telegram спільнота: https://t.me/BlockBeats_App
Twitter офіційний акаунт: https://twitter.com/BlockBeatsAsia

