Dalam pos sebelumnya, kami mengeksplorasi Sejarah Desain AplikasiPada Bagian 1 dari seri Agentic AI kedua kami, kami meneliti lanskap AI Web2 saat ini beserta tren utama, platform, dan teknologinya. Di Bagian 2, kami menjelajahi bagaimana blockchain dan verifikasi tanpa kepercayaan memungkinkan evolusi agen AI menjadi sistem yang benar-benar agentic.
1. Lanskap Agen AI Web2
Keadaan Saat Ini dari Agen Kecerdasan Buatan Terpusat

Gambar 1. Lanskap Agen AI Web2 E2B.
Lanskap kecerdasan buatan kontemporer secara dominan ditandai oleh platform dan layanan terpusat yang dikendalikan oleh perusahaan teknologi besar. Perusahaan seperti OpenAI, Anthropic, Google, dan Microsoft menyediakan model bahasa besar (LLM) dan menjaga infrastruktur cloud penting serta layanan API yang menggerakkan sebagian besar agen kecerdasan buatan.
Infrastruktur Agen AI
Kemajuan terbaru dalam infrastruktur AI telah secara mendasar mengubah bagaimana pengembang membuat agen AI. Alih-alih mengkodekan interaksi tertentu, pengembang sekarang dapat menggunakan bahasa alami untuk mendefinisikan perilaku dan tujuan agen, yang mengarah pada sistem yang lebih dapat beradaptasi dan canggih.

Gambar 2. Infrastruktur Agen AI Segmentasi.
Kemajuan kunci dalam area berikut telah mengarah pada proliferasi agen AI:
- Model Bahasa Besar Lanjutan (LLMs): LLM telah merevolusi cara agen memahami dan menghasilkan bahasa alami, menggantikan sistem berbasis aturan yang kaku dengan kemampuan pemahaman yang lebih canggih. Mereka memungkinkan penalaran dan perencanaan yang canggih melalui penalaran 'chain-of-thought'.
Sebagian besar aplikasi AI dibangun berdasarkan model LLM terpusat, seperti GPT-4 oleh OpenAI, oleh ClaudeAntropik, dan Gemini oleh Google.
Model AI sumber terbuka termasuk DeepSeek, LLaMa oleh Meta, PaLM 2 dan LaMDA oleh Google, Mistral 7B oleh Mistral AI, Grok dan Grok-1 oleh xAI, Vicuna-13B olehLM Studio, dan model Falcon oleh Technology Innovation Institute (TII). - Kerangka Agen: Beberapa kerangka kerja dan alat sedang muncul untuk memfasilitasi pembuatan aplikasi AI multi-agen untuk bisnis. Kerangka kerja ini mendukung berbagai LLM dan menyediakan fitur-fitur siap pakai untuk pengembangan agen, termasuk manajemen memori, alat kustom, dan integrasi data eksternal. Kerangka kerja ini secara signifikan mengurangi tantangan teknik, mempercepat pertumbuhan dan inovasi.
Kerangka agen teratas termasuk Phidata, Buka AI Swarm, CrewAI, LangChain LangGraph, LlamaIndex, Microsoft yang open-sourced Generasi otomatis, Vertex AI,danAliran Lang, yang menawarkan kemampuan untuk membangun asisten AI dengan pengkodean minimal yang diperlukan. - Platform AI Agen: Platform AI Agen berfokus pada pengaturan beberapa agen AI di lingkungan terdistribusi untuk memecahkan masalah kompleks secara mandiri. Sistem ini dapat beradaptasi secara dinamis dan berkolaborasi, memungkinkan solusi penskalaan yang kuat. Layanan ini bertujuan untuk mengubah cara bisnis memanfaatkan AI dengan membuat teknologi agen dapat diakses dan dapat diterapkan secara langsung ke sistem yang ada.
Platform AI agen teratas termasuk Microsoft Autogen, Langchain LangGraph, Microsoft Inti Semantik, dan CrewAI. - Retrieval Augmented Generation (RAG): Retrieval Augmented Generation (RAG) memungkinkan LLM mengakses database atau dokumen eksternal sebelum menanggapi pertanyaan, meningkatkan akurasi dan mengurangi halusinasi. Kemajuan RAG memungkinkan agen untuk beradaptasi dan belajar dari sumber informasi baru dan menghindari kebutuhan untuk melatih ulang model.
Alat RAG teratas berasal dari K2Tampilan, Tumpukan jerami, LangChain, LlamaIndex, RAGatouille, dan sumber terbuka EmbedChain dan InfiniFlow. - Sistem Memori: Untuk mengatasi keterbatasan agen AI tradisional dalam menangani tugas jangka panjang, layanan memori menyediakan memori jangka pendek untuk tugas menengah atau memori jangka panjang untuk menyimpan dan mengambil informasi untuk tugas yang diperpanjang.
Memori jangka panjang meliputi:- Memori Episodik. Merekam pengalaman spesifik untuk pembelajaran dan pemecahan masalah dan digunakan dalam konteks untuk pertanyaan saat ini.
- Memori Semantik. Informasi umum dan tingkat tinggi tentang lingkungan agen.
- Memori Prosedural. Menyimpan prosedur yang digunakan dalam pengambilan keputusan dan pemikiran langkah demi langkah yang digunakan untuk menyelesaikan masalah matematika.
- Pemimpin dalam layanan memori termasuk Letta, sumber terbuka MemGPT, Zepdan Mem0.
- Platform AI Tanpa kode: Platform No-code memungkinkan pengguna untuk membangun model AI melalui alat drag-and-drop dan antarmuka visual atau wizard tanya jawab. Pengguna dapat menyebarkan agen langsung ke aplikasi mereka dan mengotomatiskan alur kerja. Dengan menyederhanakan alur kerja agen AI, siapa pun dapat membangun dan menggunakan AI, menghasilkan aksesibilitas yang lebih besar, siklus pengembangan yang lebih cepat, dan peningkatan inovasi.
Pemimpin No-code meliputi Bangun AI, Mesin yang Dapat Diajar Google, dan Amazon SageMaker.
Ada beberapa platform no-code khusus untuk agen AI seperti Jelas AI untuk prediksi bisnis, Lobe AI untuk klasifikasi gambar, dan Nanonet untuk pemrosesan dokumen.

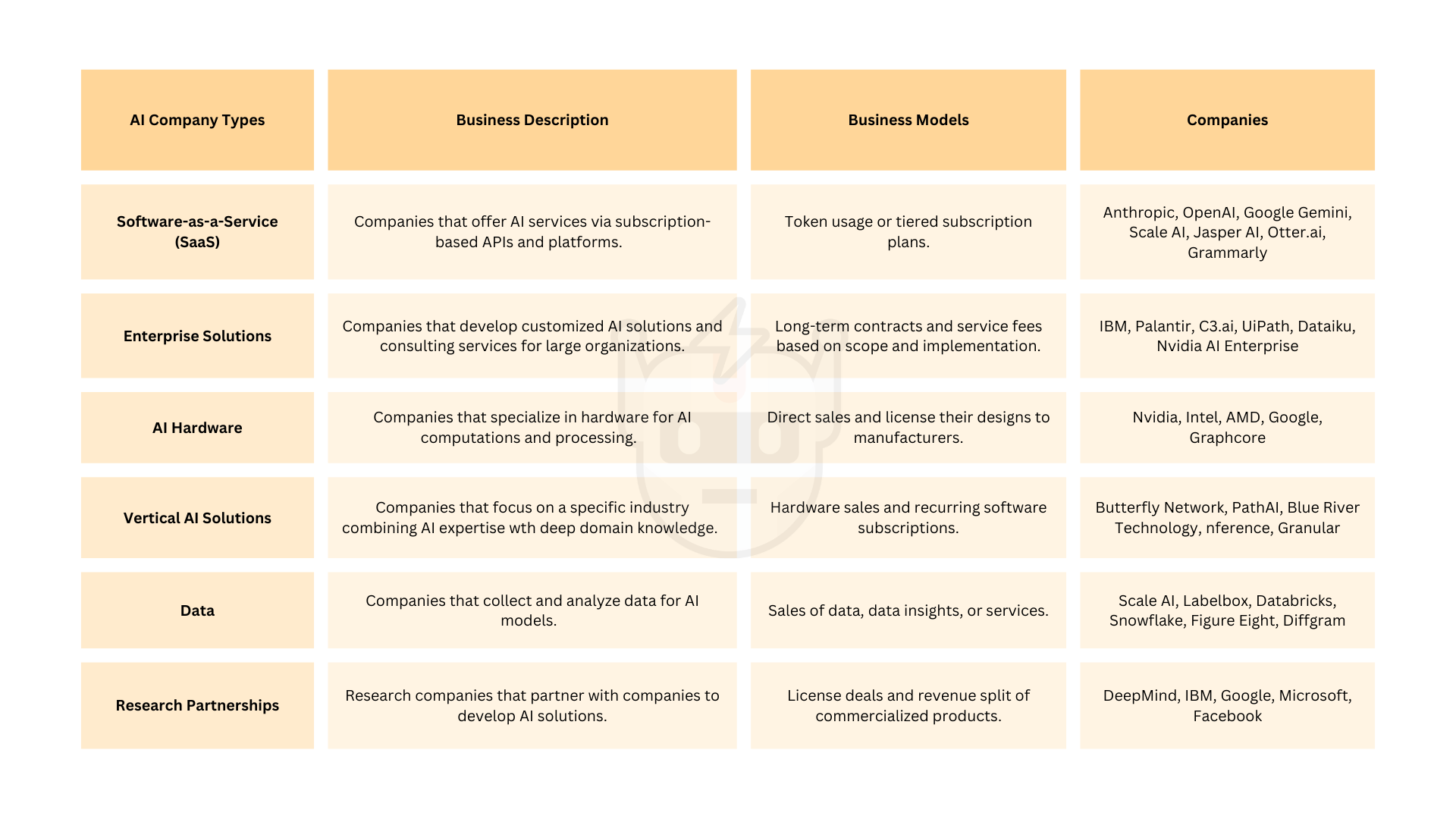
figure_3_ai_business_models1920×1080 178 KB
Gambar 3. Model Bisnis AI.
Model Bisnis
Perusahaan AI Web2 tradisional sebagian besar menggunakan langganan bertingkat dan layanan konsultasi sebagai model bisnis mereka.
Model bisnis yang muncul untuk agen AI termasuk:
- Berlangganan / Berbasis Penggunaan. Pengguna dikenai biaya berdasarkan jumlah eksekusi agen atau sumber daya komputasi yang digunakan, mirip dengan layanan Model Bahasa Besar (LLM).
- Model Marketplace. Platform agen mengambil persentase dari transaksi yang dilakukan di platform, mirip dengan model toko aplikasi.
- Lisensi Perusahaan. Solusi agen yang disesuaikan dengan biaya implementasi dan dukungan.
- Akses API. Platform agen menyediakan API yang memungkinkan pengembang mengintegrasikan agen ke dalam aplikasi mereka, dengan biaya berdasarkan panggilan API atau volume penggunaan.
- Sumber Terbuka dengan Fitur Premium. Proyek sumber terbuka menawarkan model dasar secara gratis tetapi dikenakan biaya untuk fitur lanjutan, hosting, atau dukungan perusahaan.
- Integrasi Alat. Platform agen dapat mengambil komisi dari penyedia alat untuk penggunaan atau layanan API.
2. Batasan Kecerdasan Buatan Terpusat
Sementara sistem AI Web2 saat ini telah membawa masuk suatu era baru teknologi dan efisiensi, mereka menghadapi beberapa tantangan.
- Kontrol Terpusat: Konsentrasi model AI dan data pelatihan di tangan beberapa perusahaan teknologi besar menciptakan risiko akses terbatas, pelatihan model terkontrol, dan integrasi vertikal yang dipaksakan.
- Privasi Data dan Kepemilikan: Pengguna kehilangan kendali atas bagaimana data mereka digunakan dan tidak menerima kompensasi atas penggunaannya dalam melatih sistem AI. Sentralisasi data juga menciptakan satu titik kegagalan tunggal dan dapat menjadi sasaran pelanggaran data.
- Masalah Transparansi: Sifat "kotak hitam" dari model terpusat mencegah pengguna memahami bagaimana keputusan dibuat atau memverifikasi sumber data pelatihan. Aplikasi yang dibangun di atas model ini tidak dapat menjelaskan potensi bias, dan pengguna memiliki sedikit atau tidak ada kendali atas bagaimana data mereka digunakan.
- Tantangan Peraturan: Lanskap peraturan global yang kompleks mengenai penggunaan AI dan privasi data menciptakan ketidakpastian dan tantangan kepatuhan. Agen dan aplikasi yang dibangun di atas model AI terpusat dapat tunduk pada peraturan dari negara pemilik model.
- Serangan Permusuhan: Model AI dapat rentan terhadap serangan permusuhan, di mana input dimodifikasi untuk menipu model agar menghasilkan output yang salah. Verifikasi validitas input dan output diperlukan, bersama dengan keamanan dan pemantauan agen AI.
- Keandalan Output: Output model AI memerlukan verifikasi teknis dan proses yang transparan, dapat diaudit untuk membangun kepercayaan. Saat agen AI berkembang, kebenaran output model AI menjadi sangat penting.
- Deep Fakes: gambar, ucapan, dan video yang dimodifikasi oleh kecerdasan buatan, yang dikenal sebagai “Deep Fakes,” menimbulkan tantangan signifikan karena mereka dapat menyebarkan informasi yang salah, menciptakan ancaman keamanan, dan merusak kepercayaan publik.
3. Solusi AI Terdesentralisasi
Kendala utama Web2 AI—sentralisasi, kepemilikan data, dan transparansi—sedang ditangani dengan blockchain dan tokenisasi. Web3 menawarkan solusi berikut:
- Jaringan Komputasi Terdesentralisasi. Alih-alih menggunakan penyedia cloud terpusat, model AI dapat memanfaatkan jaringan komputasi terdistribusi untuk pelatihan dan menjalankan inferensi.
- Infrastruktur Modular. Tim yang lebih kecil dapat memanfaatkan jaringan komputasi terdesentralisasi dan DAO data untuk melatih model baru yang spesifik. Pembuat dapat menambah agen mereka dengan alat modular dan primitif composable lainnya.
- Sistem yang Transparan dan Dapat Diverifikasi. Web3 dapat menawarkan cara yang dapat diverifikasi untuk melacak pengembangan dan penggunaan model dengan blockchain. Input dan output model dapat diverifikasi melalui zero-knowledge proofs (ZKP) dan lingkungan eksekusi tepercaya (TEE) dan direkam secara permanen secara on-chain.
- Kepemilikan dan Kedaulatan Data. Data dapat dimonetisasi melalui pasar atau data DAO, yang memperlakukan data sebagai aset kolektif dan dapat mendistribusikan keuntungan dari penggunaan data kepada kontributor DAO.
- Pengambilan data jaringan.**Insentif token dapat membantu jaringan bootstrap dengan memberi penghargaan kepada kontributor awal untuk komputasi terdesentralisasi, DAO data, dan pasar agen. Token dapat menciptakan insentif ekonomi langsung yang membantu mengatasi masalah koordinasi awal yang menghambat adopsi jaringan.
4. Lanskap Agen AI Web3
Tumpukan agen AI Web2 dan Web3 berbagi komponen inti seperti koordinasi model dan sumber daya, alat dan layanan lainnya, serta sistem memori untuk retensi konteks. Namun, penggabungan teknologi blockchain Web3 memungkinkan desentralisasi sumber daya komputasi, token untuk memberi insentif pada berbagi data dan kepemilikan pengguna, eksekusi tanpa kepercayaan melalui kontrak pintar, dan jaringan koordinasi bootstrap.

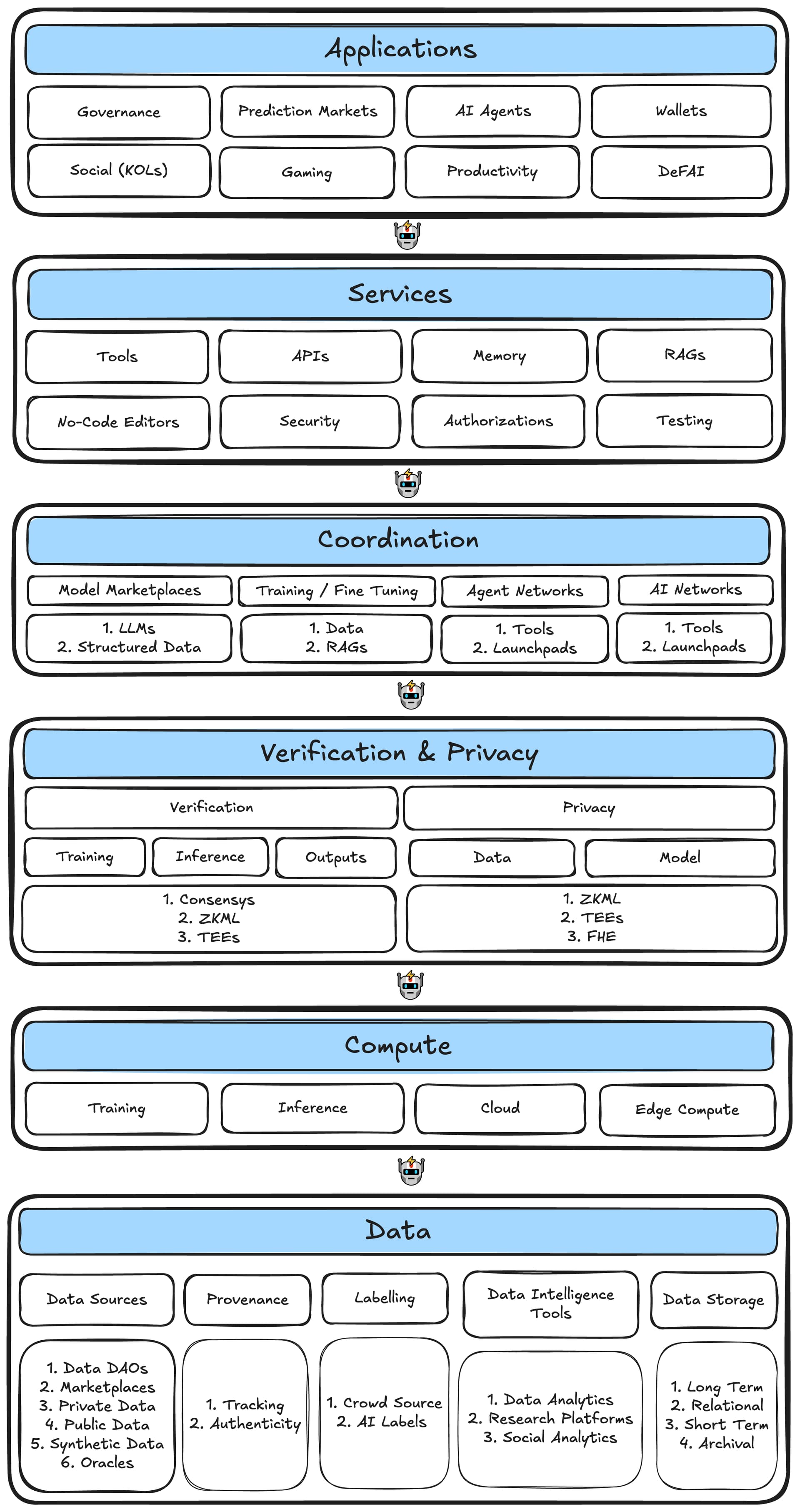
figure_4_web3_ai_agent_stack1920×3627 407 KB
Gambar 4. Tumpukan Agen AI Web3.
Data
Lapisan Data adalah dasar dari tumpukan agen AI Web3 dan mencakup semua aspek data. Ini mencakup sumber data, pelacakan asal usul dan verifikasi keaslian, sistem label, alat kecerdasan data untuk analitik dan penelitian, dan solusi penyimpanan untuk berbagai kebutuhan retensi data.
- Sumber Data. Sumber Data mewakili berbagai asal data dalam ekosistem.
- Data DAOs. Data DAOs (Vana dan Masa AI) adalah organisasi yang dikelola komunitas yang memfasilitasi berbagi data dan monetisasi.
- Pasar. Platform (Protokol SamuderadanSahara AI) membuat pasar terdesentralisasi untuk pertukaran data.
- Data Pribadi. Data sosial, keuangan, dan kesehatan dapat dianonimkan dan dibawa ke rantai untuk pengguna memonetisasi.Kaito AI mengindeks data sosial dari X dan membuat data sentimen melalui API mereka.
- Data Publik. Layanan penyusupan Web2 ( Rumput) mengumpulkan data publik dan kemudian memprosesnya menjadi data terstruktur untuk pelatihan AI.
- Data Sintetis. Data publik terbatas dan data sintetis berdasarkan data publik yang nyata telah terbukti menjadi alternatif yang cocok untuk pelatihan model AI. Mode's Subset Synth adalah kumpulan data harga sintetis yang dibuat untuk pelatihan dan pengujian model AI.
- Oracles. Oracle menggabungkan data dari sumber di luar rantai untuk terhubung dengan blockchain melalui kontrak pintar. Oracle untuk AI mencakup Protokol Ora, Chainlink, dan Masa AI.
- Asalnya. Asal data sangat penting untuk memastikan integritas data, mitigasi bias, dan reproduktifitas dalam AI. Asal data melacak asal data dan mencatat garis keturunannya.
Web3 menawarkan beberapa solusi untuk asal data, termasuk merekam asal data dan modifikasi on-chain melalui metadata berbasis blockchain (Ocean Protocol dan Asal Proyek Filecoin), melacak silsilah data melalui grafik pengetahuan terdesentralisasi (OriginTrail), dan menghasilkan bukti tanpa pengetahuan untuk asal data dan audit (Fact Fortress, Protokol Pemulihan). - Pelabelan. Pelabelan data secara tradisional mengharuskan manusia untuk menandai atau memberi label data untuk model pembelajaran yang diawasi. Insentif token dapat membantu crowdsourcing pekerja untuk prapemrosesan data.
Pada Web2, Skala AImemiliki pendapatan tahunan sebesar $1 miliar dan menghitung OpenAI, Anthropic, dan Cohere sebagai pelanggan. Dalam Web3, Protokol Manusia dan pelabelan data crowdsource Ocean Protocol dan kontributor label penghargaan dengan token. Alaya AIdanFetch.ai menggunakan agen AI untuk pelabelan data. - Alat Kecerdasan Data. Alat Kecepatan Data adalah solusi perangkat lunak yang menganalisis dan mengekstrak wawasan dari data. Mereka meningkatkan kualitas data, memastikan kepatuhan dan keamanan, dan meningkatkan kinerja model AI dengan meningkatkan kualitas data.
Perusahaan analitik blockchain termasuk Arkham, Nansen, dan Dune. Riset off-chain oleh Messaridan analisis sentimen media sosial olehKaitojuga memiliki API untuk konsumsi model AI. - Penyimpanan Data. Insentif token memungkinkan penyimpanan data terdesentralisasi, terdistribusi di seluruh jaringan node independen. Data biasanya dienkripsi dan dibagikan di beberapa node untuk menjaga redundansi dan privasi.
Filecoinadalah salah satu proyek penyimpanan data terdistribusi pertama yang memungkinkan orang untuk menawarkan ruang hard disk yang tidak terpakai mereka untuk menyimpan data terenkripsi sebagai imbalan token.IPFS(InterPlanetary File System) menciptakan jaringan peer-to-peer untuk menyimpan dan berbagi data menggunakan hash kriptografis unik.Arweavemengembangkan solusi penyimpanan data permanen yang mensubsidi biaya penyimpanan dengan imbalan blok.Storj menawarkan API yang kompatibel dengan S3 yang memungkinkan aplikasi yang ada beralih dari penyimpanan cloud ke penyimpanan terdesentralisasi dengan mudah.
Menghitung
Lapisan Komputasi menyediakan infrastruktur pemrosesan yang diperlukan untuk menjalankan operasi kecerdasan buatan. Sumber daya komputasi dapat dibagi menjadi beberapa kategori: infrastruktur pelatihan untuk pengembangan model, sistem inferensi untuk eksekusi model dan operasi agen, dan komputasi tepi untuk pemrosesan lokal terdesentralisasi.
Sumber daya komputasi terdistribusi menghilangkan ketergantungan pada jaringan awan terpusat dan meningkatkan keamanan, mengurangi masalah titik kegagalan tunggal, dan memungkinkan perusahaan kecerdasan buatan kecil untuk memanfaatkan sumber daya komputasi berlebihan.
1. Pelatihan. Pelatihan model AI memerlukan komputasi yang mahal dan intensif. Komputasi pelatihan terdesentralisasi mendemokrasikan pengembangan AI sambil meningkatkan privasi dan keamanan karena data sensitif dapat diproses secara lokal tanpa kontrol terpusat.
BittensordanJaringan Golemadalah pasar terdesentralisasi untuk sumber daya pelatihan AI.Jaringan AkashdanPhala menyediakan sumber daya komputasi terdesentralisasi dengan TEE. Jaringan Rendermengalihfungsikan jaringan GPU grafisnya untuk menyediakan komputasi untuk tugas AI.
2. Inferensi. Komputasi inferensi mengacu pada sumber daya yang dibutuhkan oleh model untuk menghasilkan output baru atau oleh aplikasi dan agen AI untuk beroperasi. Aplikasi real-time yang memproses data atau agen dalam jumlah besar yang memerlukan banyak operasi menggunakan daya komputasi inferensi dalam jumlah yang lebih besar.
Hyperbolik, Dfinitydan Hyperspacemenawarkan komputasi inferensi secara khusus. Inference LabsʻsOmronadalah pasar inferensi dan verifikasi komputasi di Bittensor. Jaringan komputasi terdesentralisasi seperti Bittensor, Jaringan Golem, Jaringan Akash, Phala, dan Jaringan Render menawarkan sumber daya komputasi pelatihan dan inferensi.
3.Edge Komputasi. Komputasi tepi melibatkan pemrosesan data secara lokal pada perangkat remote seperti ponsel pintar, perangkat IoT, atau server lokal. Komputasi tepi memungkinkan pemrosesan data secara real-time dan mengurangi laten karena model dan data berjalan secara lokal pada mesin yang sama.
Jaringan Gradien adalah jaringan komputasi tepi di Solana. Jaringan Tepi, Jaringan Theta, dan AIOZmemungkinkan komputasi tepi global.
Verifikasi / Privasi
Lapisan Verifikasi dan Privasi memastikan integritas sistem dan perlindungan data. Mekanisme konsensus, Zero-Knowledge Proofs (ZKPs), dan TEE digunakan untuk memverifikasi pelatihan model, inferensi, dan output. FHE dan TEE digunakan untuk memastikan privasi data.
1. Komputasi yang Dapat Diverifikasi. Komputasi yang dapat diverifikasi meliputi pelatihan model dan inferensi.
Phala dan Jaringan Atomamenggabungkan TEE dengan komputasi yang dapat diverifikasi.Inferiummenggunakan kombinasi ZKPs dan TEEs untuk inferensi yang dapat diverifikasi.
2. Output Proofs. Bukti output memverifikasi bahwa output model AI adalah asli dan tidak diubah tanpa memperlihatkan parameter model. Bukti output juga menawarkan provenance dan penting untuk mempercayai keputusan agen AI.
zkMLdanJaringan Azteckeduanya memiliki sistem ZKP yang membuktikan integritas output komputasi.Marlinʻs Oystermenyediakan inferensi AI yang dapat diverifikasi melalui jaringan TEE.
3.Privasi Data dan Model. FHE dan teknik kriptografi lain memungkinkan model untuk memproses data yang dienkripsi tanpa mengekspos informasi sensitif. Privasi data diperlukan saat menangani informasi pribadi dan sensitif serta untuk menjaga anonimitas.
Protokol Oasismenyediakan komputasi rahasia melalui TEEs dan enkripsi data.Partisia Blockchain menggunakan Multi-Party Computation (MPC) canggih untuk memberikan privasi data AI.
Koordinasi
Lapisan Koordinasi memfasilitasi interaksi antara komponen-komponen berbeda dari ekosistem Web3 AI. Ini mencakup pasar model untuk distribusi, infrastruktur pelatihan dan penyetelan yang baik, dan jaringan agen untuk komunikasi dan kolaborasi antar agen.
1. Model Jaringan. Jaringan model dirancang untuk berbagi sumber daya untuk pengembangan model AI.
- LLM. Model bahasa besar memerlukan sejumlah besar sumber daya komputasi dan data. Jaringan LLM memungkinkan pengembang untuk implementasi model-model khusus.
Bittensor, Mahluk, dan Akash Network menyediakan pengguna dengan sumber daya komputasi dan pasar untuk membangun LLMs di jaringan mereka. - Data Terstruktur. Jaringan data terstruktur bergantung pada kumpulan data yang disesuaikan dan dikurasi.
Pond AImenggunakan model dasar grafik untuk membuat aplikasi dan agen yang memanfaatkan data blockchain. - Marketplace. Marketplace membantu menghasilkan uang dari model AI, agen, dan kumpulan data.
Ocean Protocolmenyediakan pasar untuk data, layanan pra-pemrosesan data, model, dan output model.Ambil AIadalah pasar agen AI.
2. Pelatihan / Penyetelan Halus. Jaringan pelatihan mengkhususkan diri dalam mendistribusikan dan mengelola kumpulan data pelatihan. Jaringan fine-tuning difokuskan pada solusi infrastruktur untuk meningkatkan pengetahuan eksternal model melalui RAG (Retrieval Augmented Generation) dan API.
Bittensor, Jaringan Akash, dan Jaringan Golem menawarkan jaringan pelatihan dan penyempurnaan.
Jaringan Agen. Jaringan Agen menyediakan dua layanan utama untuk agen AI: 1) alat dan 2) peluncur agen. Alat mencakup koneksi dengan protokol lain, antarmuka pengguna standar, dan komunikasi dengan layanan eksternal. Peluncur agen memungkinkan untuk penyebaran dan pengelolaan agen AI yang mudah.
Theoriqmemanfaatkan sekelompok agen untuk mendukung solusi perdagangan DeFi. Virtuals adalah peluncur agen AI terkemuka di Base.Eliza OSadalah jaringan model LLM sumber terbuka pertama.Jaringan AlpacadanJaringan Olasadalah platform agen AI yang dimiliki oleh komunitas.
Layanan
Lapisan Layanan menyediakan middleware dan peralatan penting yang diperlukan aplikasi dan agen kecerdasan buatan agar berfungsi secara efektif. Lapisan ini mencakup alat pengembangan, API untuk integrasi data eksternal dan aplikasi, sistem memori untuk retensi konteks agen, Pemuatan dan Generasi yang Ditingkatkan (RAG) untuk akses pengetahuan yang ditingkatkan, dan infrastruktur pengujian.
- Alat. Sebuah rangkaian utilitas atau aplikasi yang memfasilitasi berbagai fungsionalitas dalam agen AI:
- Pembayaran. Mengintegrasikan sistem pembayaran terdesentralisasi memungkinkan agen untuk melakukan transaksi keuangan secara mandiri, memastikan interaksi ekonomi yang lancar dalam ekosistem Web3.
Coinbaseʻs AgentKitmemungkinkan agen AI untuk melakukan pembayaran dan transfer token. LangChain dan Pembayar menawarkan untuk mengirim dan meminta opsi pembayaran untuk agen. - Peluncur. Platform yang membantu dalam mendeploy dan memperluas agen AI, menyediakan sumber daya seperti peluncuran token, pemilihan model, API, dan akses ke alat.
Protokol Virtual adalah launchpad agen AI terkemuka yang memungkinkan pengguna membuat, menerapkan, dan memonetisasi agen AI. Top HatdanGriffainadalah peluncur agen AI di Solana. - Otorisasi. Mekanisme yang mengelola izin dan kontrol akses, memastikan agen beroperasi dalam batasan yang ditentukan dan menjaga protokol keamanan.
Biconomy menawarkan Kunci Sesiuntuk agen agar memastikan bahwa agen hanya dapat berinteraksi dengan kontrak pintar yang terdaftar dalam daftar putih. - Keamanan. Menerapkan langkah-langkah keamanan yang kuat untuk melindungi agen dari ancaman, memastikan integritas data, kerahasiaan, dan ketahanan terhadap serangan.
Keamanan GoPlusmenambahkan plug-in yang memungkinkan agen AI ElizaOS untuk menggunakan fitur keamanan on-chain yang mencegah penipuan, phishing, dan transaksi mencurigakan di sejumlah blockchain.
- Antarmuka Pemrograman Aplikasi (API). API memfasilitasi integrasi yang lancar dari data dan layanan eksternal ke agen kecerdasan buatan. API akses data memberikan akses agen ke data real-time dari sumber eksternal, meningkatkan kemampuan pengambilan keputusan mereka. API layanan memungkinkan agen untuk berinteraksi dengan aplikasi dan layanan eksternal yang memperluas fungsionalitas dan jangkauan mereka.
Jaringan Datai menyediakan data blockchain ke agen AI melalui API data terstruktur. Jaringan SubQuery menawarkan pengindeks data terdesentralisasi dan titik akhir RPC untuk agen dan aplikasi AI. - Pemulihan-Augmentasi Generasi (RAG) Augmentasi. Augmentasi RAG meningkatkan akses pengetahuan agen dengan menggabungkan LLMs dengan pengambilan data eksternal.
- Pengambilan Informasi Dinamis. Agen dapat mengambil informasi terbaru dari basis data eksternal atau internet untuk memberikan respon yang akurat dan terkini.
- Integrasi Pengetahuan. Mengintegrasikan data yang diambil ke dalam proses generasi memungkinkan agen menghasilkan output yang lebih terinformasi dan relevan konteks.
- Jaringan Atoma menawarkan kurasi data yang aman dan API data publik untuk RAG yang disesuaikan. ElizaOSdanProtokol KIPmenawarkan plugin agen ke sumber data eksternal seperti X dan Farcaster.
- Ingatan. Agen AI membutuhkan sistem memori untuk mempertahankan konteks dan belajar dari interaksi mereka. Dengan retensi konteks, agen mempertahankan riwayat interaksi untuk memberikan respons yang koheren dan sesuai secara kontekstual. Penyimpanan memori yang lebih lama memungkinkan agen untuk menyimpan dan menganalisis interaksi masa lalu yang dapat meningkatkan kinerja mereka dan mempersonalisasi pengalaman pengguna dari waktu ke waktu.
ElizaOS menawarkan manajemen memori sebagai bagian dari jaringan agennya. Mem0AI dan Unibase AIsedang membangun lapisan memori untuk aplikasi dan agen AI. - Infrastruktur Pengujian. Platform yang dirancang untuk memastikan keandalan dan ketangguhan agen AI. Agen dapat berjalan di lingkungan simulasi terkendali untuk mengevaluasi kinerja dalam berbagai skenario. Platform pengujian memungkinkan pemantauan kinerja dan penilaian terus menerus dari operasi agen untuk mengidentifikasi masalah apa pun.
Asisten AI Alchemy, Obrolan Web3, dapat menguji agen AI melalui kueri kompleks dan pengujian pada implementasi fungsi.
Aplikasi
Lapisan Aplikasi berada di bagian atas tumpukan AI dan mewakili solusi yang menghadap pengguna akhir. Ini termasuk agen yang memecahkan kasus pengguna seperti manajemen dompet, keamanan, produktivitas, penghasilan, pasar prediksi, sistem tata kelola, dan alat DeFAI.
- Dompet. Agen AI meningkatkan dompet Web3 dengan menafsirkan maksud pengguna dan mengotomatiskan transaksi yang kompleks, sehingga meningkatkan pengalaman pengguna.
Dompet ArmordanDompet Rubah menggunakan agen AI untuk mengeksekusi niat pengguna di seluruh platform DeFi dan blockchain yang memungkinkan pengguna untuk memasukkan niat mereka melalui antarmuka bergaya obrolan. Platform Pengembang Coinbasemenawarkan agen AI dompet MPC yang memungkinkan mereka mentransfer token secara otonom. - Keamanan. Agen AI memantau aktivitas blockchain untuk mengidentifikasi perilaku penipuan dan transaksi kontrak pintar yang mencurigakan.
ChainAware.aiʻs Agen Deteksi Penipuan menyediakan keamanan dompet dan pemantauan kepatuhan waktu nyata di sejumlah blockchain. AgentLayerʻs Pemeriksa Dompet memindai dompet untuk kerentanan dan menawarkan rekomendasi untuk meningkatkan keamanan. - Produktivitas. Agen AI membantu dalam mengotomatiskan tugas, mengelola jadwal, dan memberikan rekomendasi cerdas untuk meningkatkan efisiensi pengguna.
Dunia3 menampilkan platform no-code untuk merancang agen AI modular untuk tugas-tugas seperti manajemen media sosial, peluncuran token Web3, dan bantuan penelitian. - Gaming. Agen AI mengoperasikan karakter non-pemain (NPC) yang beradaptasi dengan aksi pemain secara real-time, meningkatkan pengalaman pengguna. Mereka juga dapat menghasilkan konten dalam game dan membantu pemain baru dalam mempelajari permainan.
AI Arenamenggunakan pemain manusia dan pembelajaran imitasi untuk melatih agen permainan AI.Jaringan Nim adalah rantai game AI yang menyediakan ID agen dan ZKP untuk memverifikasi agen di seluruh blockchain dan game. Game3s.GG merancang agen yang mampu menavigasi, melatih, dan bermain bersama pemain manusia. - Prediksi. Agen AI menganalisis data untuk memberikan wawasan dan memfasilitasi pengambilan keputusan yang tepat untuk platform prediksi.
Prediktor GOATadalah agen AI di Jaringan Ton yang menawarkan rekomendasi berbasis data.SynStation adalah pasar prediksi milik komunitas di Soneium yang menggunakan Agen AI untuk membantu pengguna dalam membuat keputusan. - Governance. Agen AI memfasilitasi tata kelola organisasi otonom terdesentralisasi (DAO) dengan mengotomatisasi evaluasi proposal, melakukan pengecekan suhu komunitas, memastikan pemungutan suara bebas dari Sybil, dan mengimplementasikan kebijakan.
Jaringan SyncAIfitur ini menampilkan agen AI yang bertindak sebagai perwakilan terdesentralisasi untuk sistem tata kelola Cardano. Olas menawarkan sebuah agen tata kelolayang menyusun proposal, memberikan suara, dan mengelola kas DAO. ElizaOS memiliki sebuah agenyang mengumpulkan wawasan data dari forum DAO dan Discord, memberikan rekomendasi tata kelola. - Agen DeFAI. Agen dapat menukar token, mengidentifikasi strategi penghasil hasil, menjalankan strategi perdagangan, dan mengelola keseimbangan cross-chain. Agen manajer risiko memantau aktivitas on-chain untuk mendeteksi perilaku mencurigakan dan menarik likuiditas jika diperlukan.
Protokol Agen AI Theoriqmengerahkan sekelompok agen untuk mengelola transaksi DeFi kompleks, mengoptimalkan kolam likuiditas, dan mengotomatisasi strategi pertanian hasil.Noyaadalah platform DeFi yang memanfaatkan agen AI untuk manajemen risiko dan portofolio.
Secara kolektif, aplikasi-aplikasi ini berkontribusi untuk ekosistem AI yang aman, transparan, dan terdesentralisasi yang disesuaikan dengan kebutuhan Web3.
Kesimpulan
Evolusi dari sistem AI Web2 ke Web3 mewakili perubahan mendasar dalam cara kita mendekati pengembangan dan penerapan kecerdasan buatan. Sementara infrastruktur AI terpusat Web2 telah mendorong inovasi yang luar biasa, ia menghadapi tantangan signifikan seputar privasi data, transparansi, dan kontrol terpusat. Tumpukan AI Web3 menunjukkan bagaimana sistem terdesentralisasi dapat mengatasi keterbatasan ini melalui DAO data, jaringan komputasi terdesentralisasi, dan sistem verifikasi tanpa kepercayaan. Mungkin yang paling penting, insentif token menciptakan mekanisme koordinasi baru yang dapat membantu bootstrap dan mempertahankan jaringan terdesentralisasi ini.
Melihat ke depan, munculnya agen AI mewakili wilayah baru dalam evolusi ini. Seperti yang akan kita telusuri dalam artikel berikutnya, agen AI – mulai dari bot tugas sederhana hingga sistem otonom kompleks – menjadi semakin canggih dan mampu. Integrasi agen-agen ini dengan infrastruktur Web3, dikombinasikan dengan pertimbangan hati-hati terhadap arsitektur teknis, insentif ekonomi, dan struktur tata kelola, memiliki potensi untuk menciptakan sistem yang lebih adil, transparan, dan efisien daripada yang mungkin di era Web2. Memahami bagaimana agen-agen ini bekerja, tingkat kompleksitas yang berbeda, dan perbedaan antara agen AI dan AI yang benar-benar agensial akan menjadi sangat penting bagi siapa pun yang bekerja di persimpangan antara AI dan Web3.
Disclaimer:
- Artikel ini dicetak ulang dari [GateFlashbots]. Semua hak cipta milik penulis asli [tesa]. Jika ada keberatan terhadap cetak ulang ini, harap hubungi Gate Belajartim, dan merekalah yang akan menanganinya dengan segera.
- Penafian Kewajiban: Pandangan dan pendapat yang diungkapkan dalam artikel ini semata-mata milik penulis dan bukan merupakan saran investasi apa pun.
- Tim Gate Learn melakukan terjemahan artikel ke dalam bahasa lain. Menyalin, mendistribusikan, atau melakukan plagiarisme terhadap artikel yang diterjemahkan dilarang kecuali disebutkan.









{kind=link}
{kind=link}