以前の投稿では、我々は探求しましたアプリケーションデザインの歴史第2部では、ブロックチェーンと信頼できる検証が、AIエージェントを本当にエージェントシステムに進化させる方法について探求します。
1. Web2 AI Agent Landscape
中央集権化されたAIエージェントの現状

図1. E2B Web2 AI エージェント ランドスケープ。
現代のAIの景観は主に主要なテクノロジー企業によって制御される中央集権的なプラットフォームやサービスによって特徴付けられています。 OpenAI、Anthropic、Google、Microsoftなどの企業は、大規模な言語モデル(LLM)を提供し、ほとんどのAIエージェントを駆動する重要なクラウドインフラストラクチャやAPIサービスを維持しています。
AI エージェント インフラストラクチャ
最近、AIインフラの進歩により、開発者がAIエージェントを作成する方法が根本的に変わりました。特定の相互作用をコーディングする代わりに、開発者は自然な言語を使用してエージェントの振る舞いや目標を定義できるようになり、それにより適応性と洗練されたシステムが実現されています。

図2. AIエージェントインフラストラクチャセグメンテーション。
以下の領域での重要な進展が、AIエージェントの増殖につながっています:
- 高度な大規模言語モデル(LLM):LLMは、エージェントが自然言語を理解し、生成する方法に革命をもたらし、厳格なルールベースのシステムをより洗練された理解能力に置き換えました。彼らは、「思考の連鎖」推論を通じて高度な推論と計画を可能にします。
ほとんどのAIアプリケーションは、Gateなどの中央集権的なLLMモデルに基づいて構築されています。OpenAI, ゲート クロードバイアントロピック、およびGoogleのGemini。
オープンソースのAIモデルには、MetaのDeepSeek、LLaMa、GoogleのPaLM 2およびLaMDA、Mistral 7Bなどが含まれますミストラルAI, Grok と Grok-1 by XAI、ビクーニャ-13BによるLM Studio, およびテクノロジーイノベーション研究所(TII)によるファルコンモデル。 - エージェントフレームワーク: いくつかのフレームワークやツールが新たに登場し、ビジネス向けのマルチエージェントAIアプリケーションの作成を容易にしています。これらのフレームワークはさまざまなLLMをサポートし、メモリ管理、カスタムツール、外部データ統合など、エージェント開発のための事前パッケージ化された機能を提供しています。これらのフレームワークは、エンジニアリング上の課題を大幅に軽減し、成長とイノベーションを加速させます。
トップエージェントフレームワークには、Phidata, OpenAI群れ, クルーAI, LangChain LangGraph,LlamaIndex, オープンソースのMicrosoftオートジェネレーション,頂点AI、そしてラングフロー、AIアシスタントを最小限のコーディングで構築する機能を提供します。 - エージェンティックAIプラットフォーム:エージェンティックAIプラットフォームは、分散環境で複数のAIエージェントを組み合わせて複雑な問題を自律的に解決することに焦点を当てています。これらのシステムは動的に適応し、協力して、堅牢なスケーリングソリューションを可能にします。これらのサービスは、エージェント技術を企業がAIを利用する方法を変革し、既存のシステムに直接適用できるようにすることを目指しています。
トップエージェントAIプラットフォームには、Microsoft Autogen、Langchain LangGraph、Microsoftが含まれますセマンティックカーネル、およびCrewAI。 - Retrieval Augmented Generation (RAG): リトリーバル増強生成(RAG)は、LLMがクエリに応答する前に外部データベースや文書にアクセスできるようにし、正確性を高め、幻覚を減らすことができます。 RAGの進歩により、エージェントは新しい情報源から適応し学習し、モデルの再トレーニングの必要性を回避できます。
トップのRAGツールはGate.comから提供されていますK2ビュー、Haystack, ラングチェーン,ラマインデックス, RAGatouille、およびオープンソースEmbedChainそしてInfiniFlow. - メモリシステム:従来のAIエージェントが長期タスクを処理する際の制限を克服するために、メモリサービスは、中間タスク用の短期メモリ、または拡張タスク用の情報を保存および取得するための長期メモリを提供します。
長期記憶には以下が含まれます。- エピソード記憶。学習と問題解決のための特定の経験を記録し、現在のクエリのコンテキストで使用されます。
- セマンティックメモリ。エージェントの環境に関する一般的で高レベルの情報。
- 手続き型メモリ。数学的問題を解決するために使用される意思決定と段階的な思考で使用される手順を格納します。
- メモリサービスのリーダーには、Gate.comが含まれていますLetta,オープンソースMemGPT,ゼップ、そしてMEM0.
- ノーコードAIプラットフォーム:ノーコードプラットフォームを使用すると、ユーザーはドラッグアンドドロップツールやビジュアルインターフェイス、または質疑応答ウィザードを使用してAIモデルを構築できます。ユーザーは、エージェントをアプリケーションに直接デプロイし、ワークフローを自動化できます。AIエージェントのワークフローを簡素化することで、誰でもAIを構築して使用できるため、アクセシビリティが向上し、開発サイクルが短縮され、イノベーションが増加します。
No-codeリーダーには、Gateも含まれますBuildFire AI,Googleティーチャブルマシン、および Amazonセージメーカー.
いくつかのニッチなノーコードプラットフォームが、GateなどのAIエージェント向けに存在しています。明らかにAIですビジネス予測のために、Lobe AI画像分類の場合、およびNanonetsドキュメント処理用。

figure_3_ai_business_models1920×1080 178 KB
図 3.AIビジネスモデル。
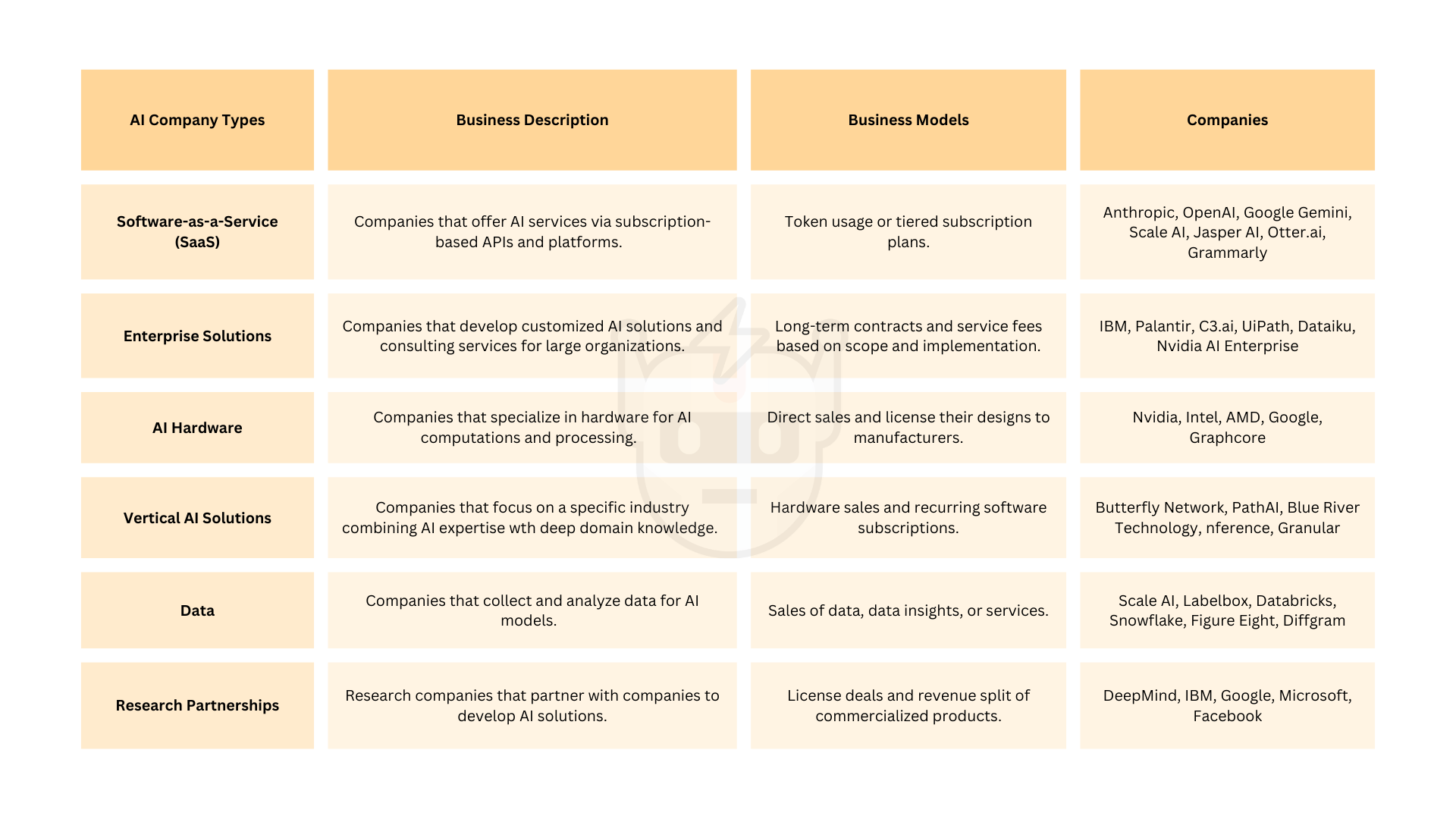{kind=link}
ビジネスモデル
従来のWeb2 AI企業は、主に階層型のサブスクリプションとコンサルティングサービスをビジネスモデルとして採用しています。
AIエージェントの新興ビジネスモデルには、Gateが含まれます。
- Subscription / Usage-Based. ユーザーは、エージェントラン数または利用された計算リソースの数に基づいて料金が請求されます。これは、Large Language Model (LLM) サービスと同様です。
- Marketplace モデル。エージェントプラットフォームは、アプリストアモデルと同様に、プラットフォーム上で行われたトランザクションの割合を取ります。
- エンタープライズライセンス。実装とサポートの費用がかかるカスタマイズされたエージェントソリューション。
- API アクセス。エージェント プラットフォームは、開発者がエージェントをアプリケーションに統合するための API を提供し、API 呼び出しや使用量に基づいて課金されます。
- プレミアム機能を備えたオープンソース。オープンソースプロジェクトは、基本モデルを無料で提供しますが、高度な機能、ホスティング、またはエンタープライズサポートは有料です。
- ツールの統合。エージェントプラットフォームは、APIの使用またはサービスに対してツールプロバイダーから手数料を受け取る場合があります。
2. 中央集権型AIの限界
現在のWeb2 AIシステムは、テクノロジーと効率性の新時代を切り開いていますが、いくつかの課題に直面しています。
- 一元管理:AIモデルとトレーニングデータが少数の大手テクノロジー企業の手に集中しているため、アクセス制限、制御されたモデルトレーニング、強制的な垂直統合のリスクが生じます。
- データのプライバシーと所有権: ユーザーは、データの使用方法を制御できず、AI システムのトレーニングでの使用に対して報酬を受け取りません。また、データの一元化は単一障害点を生み出し、データ侵害の標的になる可能性があります。
- 透明性の問題:一元化されたモデルの「ブラックボックス」の性質により、ユーザーは意思決定がどのように行われるかを理解したり、トレーニングデータソースを検証したりすることができません。これらのモデルに基づいて構築されたアプリケーションは、潜在的なバイアスを説明することができず、ユーザーはデータの使用方法をほとんどまたはまったく制御できません。
- Regulatory Challenges: AIの使用とデータプライバシーに関する複雑なグローバル規制環境は、不確実性とコンプライアンスの課題を生み出します。中央集権型AIモデルに基づいて構築されたエージェントやアプリケーションは、モデル所有者の国の規制の対象となる可能性があります。
- 敵対的攻撃: AI モデルは敵対的攻撃の影響を受けやすく、入力が変更されてモデルが欺かれ、誤った出力が生成されます。入力と出力の有効性の検証、およびAIエージェントのセキュリティと監視が必要です。
- 出力の信頼性: AI モデルの出力には、信頼性を確立するための技術的な検証と、透明で監査可能なプロセスが必要です。AIエージェントが規模を拡大するにつれて、AIモデル出力の正確性が重要になります。
- ディープフェイク:AIが改変した画像、音声、動画は「ディープフェイク」と呼ばれ、誤情報を拡散し、セキュリティ上の脅威を生み出し、国民の信頼を損なう可能性があるため、大きな課題となっています。
3. 分散型AIソリューション
Web2 AIの主要な制約条件—中央集権化、データ所有権、透明性—は、ブロックチェーンとトークン化によって解決されつつあります。Web3は以下の解決策を提供しています:
- 分散コンピューティングネットワーク。中央集権型のクラウドプロバイダーを使用せずに、AIモデルは分散コンピューティングネットワークを利用してトレーニングおよび推論を実行することができます。
- Modular Infrastructure. より小さなチームは、分散コンピューティングネットワークとデータDAOを活用して、新しい特定のモデルをトレーニングすることができます。 ビルダーは、モジュラーツールや他の合成可能なプリミティブでエージェントを補完することができます。
- 透明で検証可能なシステム。Web3は、ブロックチェーンを使用してモデルの開発と利用を追跡する検証可能な方法を提供できます。モデルの入力と出力は、ゼロ知識証明(ZKP)および信頼された実行環境(TEE)を介して検証され、永続的にチェーン上に記録されます。
- データ所有権と主権。データは、データを共同資産として扱い、データの利用から利益をDAOの貢献者に再配分することができるマーケットプレイスやデータDAOを通じて収益化されることができます。
- ネットワークブートストラップ。**トークンインセンティブは、分散型コンピューティング、データDAO、エージェントマーケットプレイスの早期貢献者に報酬を与えることで、ネットワークのブートストラップを支援します。トークンは、ネットワークの採用を妨げる初期の調整問題を克服するのに役立つ即時の経済的インセンティブを生み出すことができます。
4. Web3 AIエージェントのランドスケープ
Web2とWeb3のAIエージェントスタックは、モデルやリソースの調整、ツールやその他のサービス、コンテキストの保持のためのメモリシステムなど、コアコンポーネントを共有しています。ただし、Web3はブロックチェーン技術の組み込みにより、計算リソースの分散化、データ共有とユーザー所有権を促進するトークン、スマートコントラクトを介した信頼できる実行、およびブートストラップされた調整ネットワークを可能にしています。

figure_4_web3_ai_agent_stack1920×3627 407 KB
図 4.Web3 AIエージェントスタック。
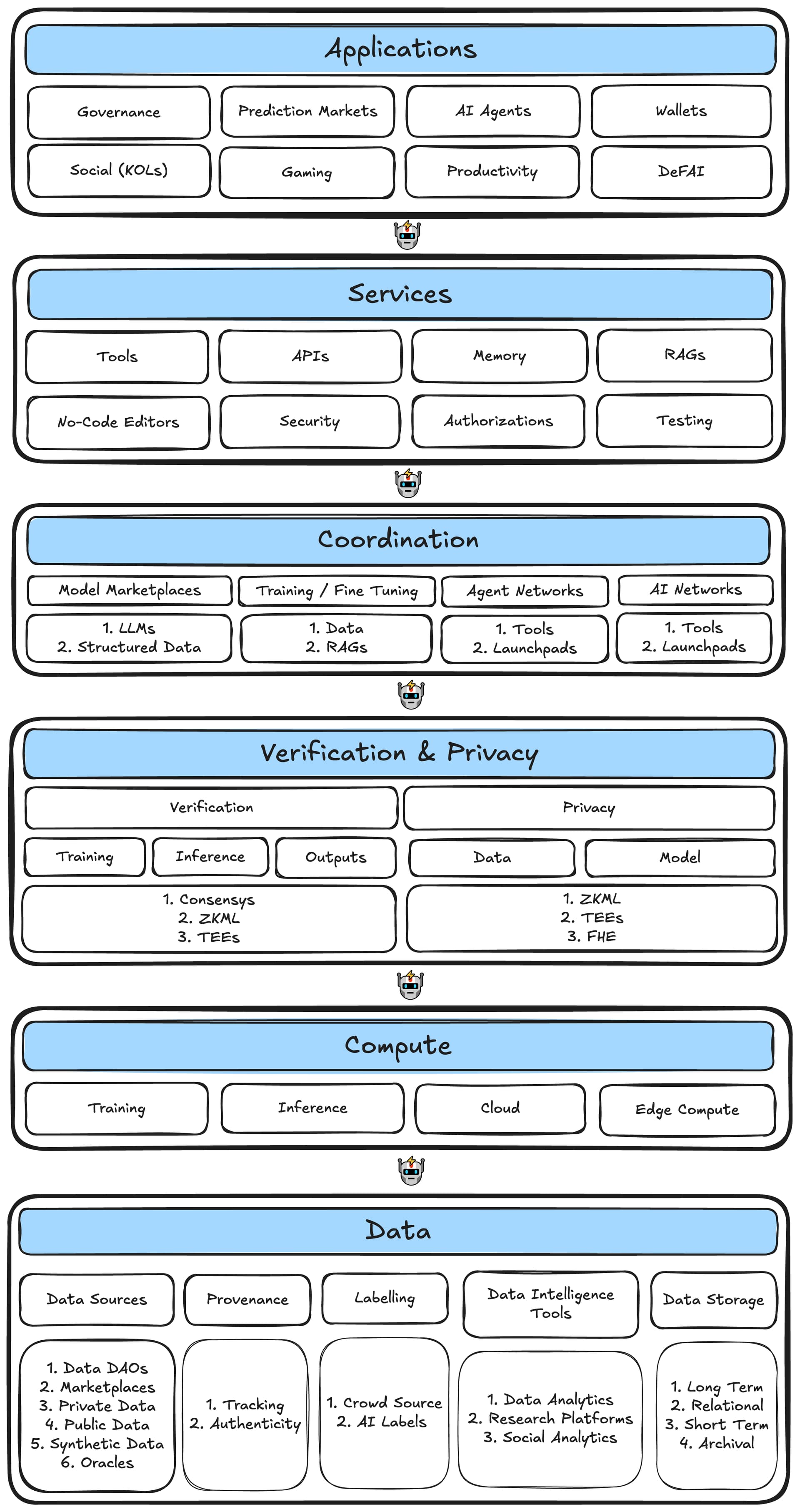{kind=link}
データ
データレイヤーは、Web3 AIエージェントスタックの基盤であり、データのあらゆる側面を網羅しています。これには、データソース、来歴の追跡と信頼性の検証、ラベリングシステム、分析と研究のためのデータインテリジェンスツール、さまざまなデータ保持ニーズに対応するストレージソリューションが含まれます。
- データ ソース。データソースは、エコシステム内のデータのさまざまな出所を表します。
- データDAO。データ DAO (ヴァナそしてMasa AI)は、データ共有と収益化を促進するコミュニティランの組織です。
- マーケットプレイス。プラットフォーム (Ocean ProtocolそしてサハラAIデータ交換のための分散型マーケットを作成します。
- 個人データ。ソーシャルデータ、財務データ、ヘルスケアデータを匿名化し、オンチェーンに持ち込んでユーザーが収益化できるようにすることができます。カイトAIXからソーシャルデータをインデックスし、そのAPIを使用してセンチメントデータを作成します。
- Public Data. Web2スクレイピングサービス(草)公開データを収集し、それをAIトレーニング用の構造化データに前処理します。
- 合成データ。公開データは限られており、実際の公開データに基づいた合成データは、AIモデルのトレーニングに適した代替手段として証明されています。モードのシンセサブセットは、AIモデルのトレーニングとテストのために構築された合成価格データセットです。
- 神託。オラクルは、オフチェーンソースからデータを集約し、スマートコントラクトを介してブロックチェーンに接続します。AIのオラクルには以下が含まれますオラプロトコル、チェーンリンク、そしてマサアイ。
- 起源。データの起源は、AIにおいてデータの整合性、バイアスの軽減、再現性を確保するために極めて重要です。データの起源は、データの起源を追跡し、その系統を記録します。
Web3は、データの出所や変更履歴をブロックチェーンベースのメタデータ(Ocean ProtocolやFilecoinのProject Origin)を使ってチェーン上に記録するなど、データの信頼性向上に向けたいくつかのソリューションを提供しています。オリジントレイル)、データの出所と監査のためのゼロ知識証明の作成(Fact Fortress、リクレイムプロトコル) - ラベリング。データのラベル付けは、従来、教師あり学習モデルのために人間がデータにタグを付けたり、ラベルを付けたりする必要がありました。トークンインセンティブは、データの前処理のためにワーカーをクラウドソーシングするのに役立ちます。
Web2では、AI のスケーリング年間売上高は10億ドルで、OpenAI、Anthropic、Cohereを顧客として数えています。Web3では、Human ProtocolOcean Protocolはデータラベリングをクラウドソーシングし、ラベルの貢献者にトークンを報酬として提供します。アラヤAIそしてFetch.aiデータラベリングにはAIエージェントを雇用します。 - データインテリジェンスツール。データインテリジェンスツールは、データを分析し洞察を抽出するソフトウェアソリューションです。データ品質を向上させ、コンプライアンスとセキュリティを確保し、データ品質を向上させることでAIモデルのパフォーマンスを向上させます。
ブロックチェーン分析会社には、アーカム,Nansen, そして DUNE. オフチェーンリサーチ by Messariおよびソーシャルメディアセンチメント分析によるカイトAIモデル消費のためのAPIもあります。 - データストレージ。トークンインセンティブは、独立したノードネットワーク全体で分散型のデータストレージを可能にします。通常、データは暗号化され、冗長性とプライバシーを維持するために複数のノード間で共有されます。
Filecoinは、トークンと引き換えに暗号化されたデータを保存するために未使用のハードドライブスペースを提供できるようにする最初の分散型データストレージプロジェクトの1つでした。IPFS(InterPlanetary File System)は、固有の暗号ハッシュを使用してデータを保存および共有するためのピア・ツー・ピア・ネットワークを作成します。Arweave開発された永続的なデータストレージソリューションは、ブロック報酬でストレージコストを補助します。STORJは、既存のアプリケーションをクラウドストレージから分散型ストレージに簡単に切り替えることができるS3互換APIを提供します。
Compute
Computeレイヤーは、AIオペレーションを実行するために必要な処理インフラを提供します。コンピューティングリソースは、次の距離カテゴリに分けることができます: モデル開発のためのトレーニングインフラ、モデルの実行およびエージェントオペレーション用の推論システム、およびローカル分散処理用のエッジコンピューティング。
分散コンピューティングリソースは、中央集権的なクラウドネットワークへの依存を取り除き、セキュリティを向上させ、単一障害点の問題を軽減し、小規模なAI企業が余剰のコンピューティングリソースを活用できるようにします。
1. トレーニング。AIモデルのトレーニングは計算量が多く、集中的です。分散トレーニングコンピュートはAI開発を民主化し、機密性とセキュリティを高めます。中央集権的な制御なしでローカルでデータを処理できるためです。
BittensorそしてゴーレムネットワークAIトレーニングリソースの分散型マーケットプレイスです。Akash NetworkとPhalaTEEを使用して分散コンピューティングリソースを提供します。レンダーネットワークグラフィックGPUネットワークを再利用して、AIタスクのためのコンピューティングを提供しています。
2. 推論。 推論コンピューティングとは、モデルが新しい出力を生成するために必要とするリソース、またはAIアプリケーションやエージェントが動作するために必要とするリソースを指します。大量のデータを処理するリアルタイムアプリケーションや、複数の操作を必要とするエージェントは、より多くの推論コンピューティングパワーを使用します。
双曲線的, Dfinity, そして ハイパースペースspecifically offer inference computing. Inference LabsʻsオムロンBittensor上の推論および検証マーケットプレイスです。Bittensor、Golem Network、Akash Network、Phala、およびRender Networkなどの分散コンピューティングネットワークは、トレーニングおよび推論コンピューティングリソースの両方を提供しています。
3.エッジコンピューティング。エッジコンピューティングは、スマートフォン、IoTデバイス、またはローカルサーバーなどのリモートデバイスでデータをローカルで処理することを意味します。エッジコンピューティングにより、モデルとデータが同じマシン上でローカルで実行されるため、リアルタイムのデータ処理とレイテンシーの低減が可能となります。
グラディエントネットワークSolana上のエッジコンピューティングネットワークです。エッジネットワーク, Theta NetworkそしてAIOZグローバルエッジコンピューティングを可能にする。
Verification / プライバシー
検証およびプライバシーレイヤーは、システムの整合性とデータ保護を確保します。コンセンサスメカニズム、ゼロ知識証明(ZKP)、およびTEEが、モデルのトレーニング、推論、および出力を検証するために使用されています。FHEおよびTEEが、データプライバシーを確保するために使用されています。
1.検証可能な計算。検証可能な計算には、モデルのトレーニングと推論が含まれます。
Phala と Atoma Network検証可能なコンピュートとTEEを組み合わせます。インフェリウム検証可能な推論にはZKPとTEEの組み合わせが使用されています。
2.出力証明。出力証明は、AIモデルの出力が本物であり、モデルパラメータを明らかにせずに改ざんされていないことを検証します。出力証明は、出自を提供し、AIエージェントの意思決定を信頼するために重要です。
zkMLのそしてアステカネットワークどちらも、計算出力の完全性を証明するZKPシステムを備えています。Marlinʻs Oyster提供されるTEEネットワークを通じた検証可能なAI推論。
3.データとモデルのプライバシー。FHEおよびその他の暗号技術により、モデルは機密情報を公開せずに暗号化されたデータを処理することができます。個人情報や機密情報を取り扱う際にはデータプライバシーが必要であり、匿名性を保つためにも重要です。
オアシスプロトコルTEEおよびデータ暗号化を介した機密コンピューティングを提供します。パルチシアブロックチェーンGateはAIデータプライバシーを提供するために、高度なMulti-Party Computation(MPC)を使用しています。
調整
コーディネーションレイヤーは、Web3 AIエコシステムのさまざまなコンポーネント間の相互作用を促進します。これには、ディストリビューション、トレーニング、およびインフラストラクチャの微調整のためのモデルマーケットプレイスと、エージェント間の通信とコラボレーションのためのエージェントネットワークが含まれます。
1.ネットワークをモデル化します。モデルネットワークは、AIモデル開発のためのリソースを共有するように設計されています。
- LLMs. 大規模言語モデルは、膨大な計算リソースとデータリソースが必要です。LLMネットワークを使用することで、開発者は専門のモデルを展開できます。
Bittensor, Sentient,そしてAkash NetworkはユーザーにコンピューティングリソースとLLMsを構築するためのマーケットプレイスを提供します。 - 構造化データ。構造化データネットワークは、カスタマイズされたキュレーションされたデータセットに依存しています。
Pond AIグラフの基盤モデルを使用して、ブロックチェーンデータを利用するアプリケーションとエージェントを作成します。 - マーケットプレイス。マーケットプレイスは、AIモデル、エージェント、およびデータセットを収益化するのに役立ちます。
オーシャンプロトコルデータ、データ前処理サービス、モデル、およびモデルの出力のマーケットプレイスを提供しています。Fetch AIAIエージェントマーケットプレイスです。
2.トレーニング / ファインチューニング。トレーニングネットワークは、トレーニングデータセットの配布と管理に特化しています。ファインチューニングネットワークは、RAG(Retrieval Augmented Generation)やAPIを通じてモデルの外部知識を強化するためのインフラソリューションに焦点を当てています。
Bittensor、Akash Network、およびGolem Networkはトレーニングと微調整ネットワークを提供しています。
3. エージェントネットワーク。 エージェントネットワークは、AIエージェント向けの主要なサービスを提供します:1)ツールと2)エージェントランチパッド。 ツールには他のプロトコルとの接続、標準化されたユーザーインターフェイス、外部サービスとの通信が含まれます。 エージェントランチパッドを使用すると、簡単にAIエージェントの展開と管理が可能になります。
Theoriqエージェントスワームを活用してDeFiトレーディングソリューションを実現します。VirtualsはBaseでトップのAIエージェントランチパッドです。Eliza OSは、最初のオープンソースLLMモデルネットワークでした。アルパカネットワーク and オラスネットワークはコミュニティ所有のAIエージェントプラットフォームです。
サービス
サービスレイヤーは、AIアプリケーションとエージェントが効果的に機能するために必要な基本的なミドルウェアとツールを提供します。このレイヤーには、開発ツール、外部データとアプリケーション統合のためのAPI、エージェントコンテキスト保持のためのメモリシステム、知識アクセスを強化するためのRetrieval-Augmented Generation(RAG)、およびテストインフラストラクチャが含まれます。
- ツール。AIエージェント内のさまざまな機能を容易にするユーティリティやアプリケーションのスイート。
- 支払い。分散型支払いシステムを統合することで、エージェントが自律的に金融取引を行い、Web3エコシステム内でシームレスな経済的相互作用を確保できます。
CoinbaseのエージェントキットAIエージェントが支払いを行い、トークンを転送できるようにします。LangChain とペイマンエージェント向けの送金および支払いオプションの提供 - ランチパッド。AIエージェントのデプロイとスケーリングを支援するプラットフォームであり、トークンの起動、モデルの選択、API、ツールへのアクセスなどのリソースを提供します。
バーチャルスプロトコルは、ユーザーがAIエージェントを作成、展開、および収益化することを可能にするAIエージェントローンチパッドです。トップハットそしてGriffainSolana上のAIエージェントランチパッドです。 - 認可。権限とアクセス制御を管理するメカニズムにより、エージェントが定義された境界内で動作し、セキュリティプロトコルが維持されるようにします。
Biconomyが提供するセッションキーエージェントがホワイトリストに登録されたスマートコントラクトとのみやり取りできるようにするために、エージェントが必要です。 - 安全。エージェントを脅威から保護するための堅牢なセキュリティ対策を実装し、データの整合性、機密性、および攻撃に対する回復力を確保します。
GoPlusセキュリティElizaOS AIエージェントが複数のブロックチェーン全体で詐欺、フィッシング、および怪しい取引を防ぐオンチェーンセキュリティ機能を利用するためのプラグインを追加しました。
- 支払い。分散型支払いシステムを統合することで、エージェントが自律的に金融取引を行い、Web3エコシステム内でシームレスな経済的相互作用を確保できます。
- アプリケーション・プログラミング・インターフェース (API)。APIは、外部データとサービスのAIエージェントへのシームレスな統合を促進します。データアクセスAPIは、エージェントが外部ソースからのリアルタイムデータにアクセスできるようにし、意思決定能力を強化します。サービス API を使用すると、エージェントは外部のアプリケーションやサービスと対話して、その機能と範囲を拡大できます。
Datai NetworkAIエージェントに構造化されたデータAPIを介してブロックチェーンデータを提供します。SubQuery Networkは、AIエージェントとアプリケーション用の分散型データインデクサーとRPCエンドポイントを提供します。 - Retrieval-Augmented Generation (RAG) オーグメンテーション。RAG拡張は、LLMと外部データ検索を組み合わせることで、エージェントの知識アクセスを強化します。
- 動的な情報検索。エージェントは、外部データベースまたはインターネットから最新の情報を取得して、正確で最新の応答を提供できます。
- ナレッジの統合。取得したデータを生成プロセスに統合することで、エージェントはより多くの情報に基づいた、コンテキストに関連した出力を生成できます。
- Atoma NetworkセキュアなデータキュレーションとカスタマイズされたRAG向けのパブリックデータAPIを提供します。ElizaOSそしてKIPプロトコルXやFarcasterなどの外部データソースにエージェントプラグインを提供します。
- メモリ。AIエージェントには、コンテキストを保持し、相互作用から学習するためのメモリシステムが必要です。コンテキストを保持することで、エージェントは過去の相互作用の履歴を維持し、一貫した文脈に即した応答を提供します。より長いメモリストレージにより、エージェントは過去の相互作用を保存および分析し、パフォーマンスを向上させ、時間とともにユーザーエクスペリエンスを個別化することができます。
ElizaOSエージェントネットワークの一環としてメモリ管理を提供します。Mem0AI and Unibase AIAIアプリケーションとエージェントのためのメモリーレイヤーを構築しています。 - テストインフラストラクチャ。AIエージェントの信頼性と堅牢性を確保するように設計されたプラットフォーム。エージェントは、制御されたシミュレーション環境で実行して、さまざまなシナリオでのパフォーマンスを評価できます。テストプラットフォームにより、パフォーマンスの監視とエージェントの操作の継続的な評価が可能になり、問題を特定できます。
アルケミーのAIアシスタント、ChatWeb3、AIエージェントを複雑なクエリや機能実装のテストを通じてテストすることができます。
アプリケーション
アプリケーション層はAIスタックのトップに位置し、エンドユーザー向けのソリューションを表します。これには、ウォレット管理、セキュリティ、生産性、取得、予測市場、ガバナンスシステム、およびDeFAIツールなどのユースケースを解決するエージェントが含まれます。
- 財布。AIエージェントは、ユーザーの意図を解釈し、複雑な取引を自動化することでWeb3ウォレットを強化し、ユーザーエクスペリエンスを向上させます。
アーマーウォレットそしてフォックスウォレットAIエージェントを利用して、ユーザーがチャットスタイルのインターフェースを介して意図を入力できるようにし、DeFiプラットフォームやブロックチェーン上でユーザーの意図を実行するCoinbaseの開発者プラットフォームAIエージェントにMPCウォレットを提供し、トークンを自律的に転送できるようにします。 - 安全。AIエージェントは、ブロックチェーンの活動を監視して、不正行為や疑わしいスマートコントラクト取引を特定します。
ChainAware.aiFraud Detector Agentは、複数のブロックチェーンにわたるリアルタイムのウォレットセキュリティとコンプライアンス監視を提供します。エージェントレイヤーウォレットチェッカーウォレットの脆弱性をスキャンし、セキュリティを強化するための推奨事項を提供します。 - 生産性。AIエージェントは、タスクの自動化、スケジュールの管理、およびユーザーの効率を高めるためのインテリジェントな推奨事項の提供を支援します。
ワールド3機能は、ソーシャルメディアの管理、Web3トークンの展開、研究支援などのタスク用にモジュラーAIエージェントを設計するためのノーコードプラットフォームを提供しています。 - ゲーム。AIエージェントは、プレイヤーの行動にリアルタイムで適応するノンプレイヤーキャラクター(NPC)を操作し、ユーザーエクスペリエンスを向上させます。また、ゲーム内コンテンツを生成し、新しいプレイヤーがゲームを学ぶのを支援することもできます。
AIアリーナ人間のプレーヤーと模倣学習を使用して、AIゲームエージェントを訓練します。ニムネットワークは、ブロックチェーンやゲーム全体でエージェントを検証するためのエージェントIDとZKPを提供するAIゲームチェーンです。Game3s.GG人間のプレーヤーと一緒にナビゲートし、コーチングし、プレイできるエージェントを設計します。 - 予測。AIエージェントは、データを分析して洞察を提供し、予測プラットフォームのための情報に基づいた意思決定を促進します。
GOATsプレディクターTonネットワーク上のAIエージェントで、データに基づいた推薦を提供しています。SynStationは、Soneiumのコミュニティ所有の予測市場であり、AIエージェントを使用してユーザーの意思決定を支援します。 - 統治。AIエージェントは、提案評価の自動化、コミュニティの温度チェックの実施、シビルフリー投票の確保、ポリシーの実施により、分散型自律組織(DAO)のガバナンスを促進します。
SyncAI NetworkCardanoのガバナンスシステムの分散型代表として機能するAIエージェントを備えています。Olasは、ガバナンスエージェント提案を起案し、投票を行い、DAOの財務を管理します。ElizaOSはエージェントDAOフォーラムとDiscordからデータ洞察を収集し、ガバナンスの推奨事項を提供するものです。 - DeFAIエージェント。 エージェントはトークンを交換し、イールドを生み出す戦略を特定し、取引戦略を実行し、クロスチェーンのリバランスを管理します。リスクマネージャーエージェントはオンチェーンのアクティビティを監視して不審な行動を検出し、必要に応じて流動性を引き出します。
TheoriqのAIエージェントプロトコルエージェントの群れを展開し、複雑なDeFi取引を管理し、流動性プールを最適化し、収量のファーミング戦略を自動化します。ノヤAIエージェントを活用したリスク管理とポートフォリオ管理を行うDeFiプラットフォームです。
これらのアプリケーションは、Web3のニーズに合わせた安全で透明で分散化されたAIエコシステムに貢献しています。
結論
Web2からWeb3のAIシステムへの進化は、人工知能の開発と展開におけるアプローチの根本的な変化を表しています。Web2の中央集権的なAIインフラは、膨大なイノベーションをもたらしてきましたが、データプライバシー、透明性、中央集権の制御に関する重大な課題に直面しています。Web3のAIスタックは、データDAO、分散型コンピューティングネットワーク、信頼できる検証システムを通じて、これらの制限に対処できる方法を示しています。おそらく最も重要なのは、トークンインセンティブが、これらの分散型ネットワークを立ち上げ、維持するのに役立つ新しい調整メカニズムを生み出していることです。
AIエージェントの台頭は、この進化における次のフロンティアを表しています。次の記事で探求するように、AIエージェント-単純なタスク固有のボットから複雑な自律システムまで-は、ますます洗練され、能力を持っています。これらのエージェントをWeb3インフラストラクチャと統合し、技術アーキテクチャ、経済的インセンティブ、およびガバナンス構造の慎重な考慮と組み合わせることで、Web2時代では可能だったものよりも公正で透明で効率的なシステムを作成する可能性があります。これらのエージェントがどのように機能し、異なる複雑さのレベル、AIエージェントと本当にエージェント的なAIの違いを理解することは、AIとWeb3の交差点で活動しているすべての人にとって重要になります。
免責事項:
- この記事は[から転載されましたフラッシュボット]. すべての著作権は元の著者に帰属します[tesa]. If there are objections to this reprint, please contact the Gate Learnチーム、そして彼らは迅速に処理します。
- 責任の免責事項:本文に表現されている意見は、著者個人のものであり、投資アドバイスを構成するものではありません。
- Gate Learnチームは、記事を他の言語に翻訳します。翻訳された記事のコピー、配布、または盗用は、明示されていない限り禁止されています。
共有


関連記事

AI分野におけるRenderの申請理由:分散型ハッシュレートが人工知能の発展を支える仕組み

Render、io.net、Akash:DePINハッシュレートネットワークの比較分析

GateClawとAI Skills:Web3 AIエージェント能力フレームワークの徹底分析

GateClawの中核機能:Web3 AI Agent Workstationの技術的な概要

Fartcoinとは何か?FARTCOINについて知っておくべきすべて
