Blum45
現在、コンテンツはありません
Blum45
真に効果的なAIプロンプトの作り方
あなたはLLMに高品質なレポートを依頼し
専門家レベルの自信を持って書かれたテキストを返してもらう
しかし、その内容は全くのデタラメだったりする
馴染みがある?
だから、こういった状況を避けるために
これらの基本ポイントを理解する必要がある:
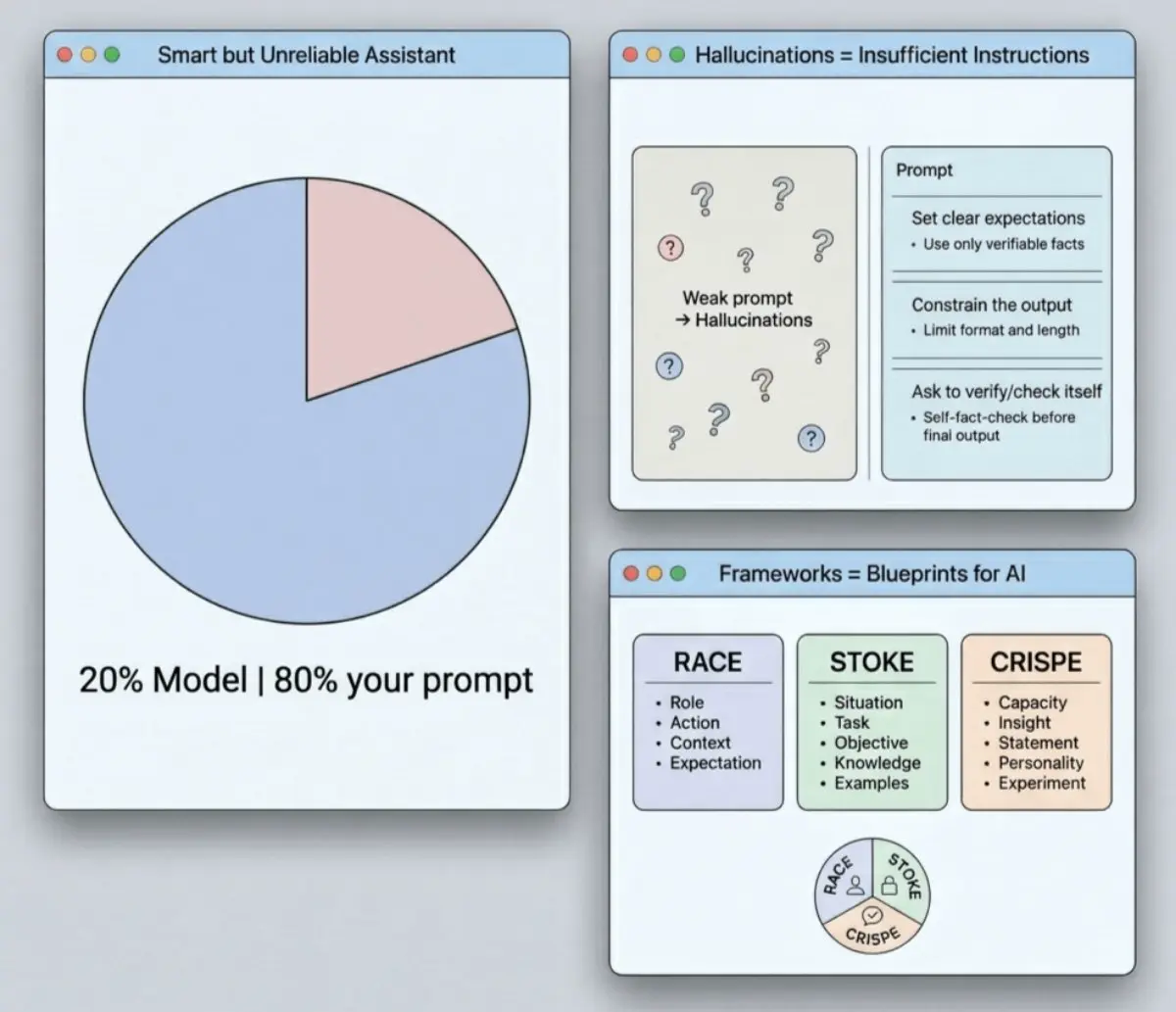
> 「賢いが信頼できない」アシスタントの問題
LLMの出力は20%がモデル本体、80%はプロンプトの構成次第
プロンプトエンジニアリング - ただの自然言語コンピューティング制御の徹底
だから、質の高い出力を得るには
モデルと会話するのをやめて、プログラムすることが必要
> AI幻覚 - 不十分な指示の兆候
確実に基盤を固めるために、次のテクニックを使おう:
- 明確な期待値を設定する
- 出力を制約する (厳格な境界を設定)
- 自己検証/自己確認をさせる (セルフファクトチェック)
> フレームワーク - AIのための「青写真」
トップ3:
- RACE (役割、行動、文脈、期待)
迅速でシンプル、日常的な利用に最適
- STOKE (状況、タスク、目的、知識、例)
深い作業やニッチな分野に適している
- CRISPE (能力、洞察、声明、個性、実験)
創造性、仮説検証、スタイル制御
LLMsはこうした構造をはるかに得意とする
その結果、出力は実際に望むものにかなり近づく
無意味な再プロンプトでAIの使
原文表示あなたはLLMに高品質なレポートを依頼し
専門家レベルの自信を持って書かれたテキストを返してもらう
しかし、その内容は全くのデタラメだったりする
馴染みがある?
だから、こういった状況を避けるために
これらの基本ポイントを理解する必要がある:
> 「賢いが信頼できない」アシスタントの問題
LLMの出力は20%がモデル本体、80%はプロンプトの構成次第
プロンプトエンジニアリング - ただの自然言語コンピューティング制御の徹底
だから、質の高い出力を得るには
モデルと会話するのをやめて、プログラムすることが必要
> AI幻覚 - 不十分な指示の兆候
確実に基盤を固めるために、次のテクニックを使おう:
- 明確な期待値を設定する
- 出力を制約する (厳格な境界を設定)
- 自己検証/自己確認をさせる (セルフファクトチェック)
> フレームワーク - AIのための「青写真」
トップ3:
- RACE (役割、行動、文脈、期待)
迅速でシンプル、日常的な利用に最適
- STOKE (状況、タスク、目的、知識、例)
深い作業やニッチな分野に適している
- CRISPE (能力、洞察、声明、個性、実験)
創造性、仮説検証、スタイル制御
LLMsはこうした構造をはるかに得意とする
その結果、出力は実際に望むものにかなり近づく
無意味な再プロンプトでAIの使
- 報酬
- 2
- コメント
- リポスト
- 共有
Claude - AI競争でギアを上げ始めた最速の競争者
Anthropicがどれほどの勢いでAI競争を制圧しているか、みんな理解していない
このクレイジーなチームは、わずか52日間で72回のリリースを実現した
さらに言えば、その多くは本当に素晴らしい成果だ
主な内容:
> モデル&コアプラットフォーム
- Opus 4.6: 100万コンテキストにアップグレードされたフラッグシップ
- Sonnet 4.6: 能力的に進化したミッドティアモデル
- Fast Opus 4.6: 実験的な2.5倍高速フラッグシップ
- 100万コンテキスト: 有料プランの圧倒的なコンテキスト拡張
> 開発者ツール
- Agent Teams: 複雑なタスク向けの並列エージェント
- Auto Mode: セーフガード付き自動権限判定
- Code Review: マルチエージェント並列バグハンティング
- Voice Mode: プッシュトークン音声コマンド
- Security: コードベース脆弱性の自動スキャン
> デスクトップオートメーション
- Computer Use: マウスとキーボードの直接制御
- Cowork Dispatch: 常時稼働する永続的なバックグラウンドエージェント
- Cowork for Windows: 完全なデスクトップアプリパリティ
- Scheduled
原文表示Anthropicがどれほどの勢いでAI競争を制圧しているか、みんな理解していない
このクレイジーなチームは、わずか52日間で72回のリリースを実現した
さらに言えば、その多くは本当に素晴らしい成果だ
主な内容:
> モデル&コアプラットフォーム
- Opus 4.6: 100万コンテキストにアップグレードされたフラッグシップ
- Sonnet 4.6: 能力的に進化したミッドティアモデル
- Fast Opus 4.6: 実験的な2.5倍高速フラッグシップ
- 100万コンテキスト: 有料プランの圧倒的なコンテキスト拡張
> 開発者ツール
- Agent Teams: 複雑なタスク向けの並列エージェント
- Auto Mode: セーフガード付き自動権限判定
- Code Review: マルチエージェント並列バグハンティング
- Voice Mode: プッシュトークン音声コマンド
- Security: コードベース脆弱性の自動スキャン
> デスクトップオートメーション
- Computer Use: マウスとキーボードの直接制御
- Cowork Dispatch: 常時稼働する永続的なバックグラウンドエージェント
- Cowork for Windows: 完全なデスクトップアプリパリティ
- Scheduled
- 報酬
- 3
- 3
- 1
- 共有
Netcafe:
さあ行こうもっと見る

Good Stake -> 生産的なエージェント
多くの人々は、AIエージェントは単によく書かれたプロンプトに過ぎないと信じています
それを超えて、適切なエージェント部品を選択することは非常に重要です:
> LLM
> ツール
> メモリ
> トリガー
> フィードバックループ
単一のポイントではありません - エージェントは単なる空の話し手です
1. LLM:推論エンジン
この部分は目的、行動方針、実行設計を定義します。
しかし、LLM自体はあなたのシステムに自動アクセスしたり、安定したコンテキストを保持したり、現実世界で行動したりしません
だから「単にGPTを使う」ことはエージェントを構築することと同じではありません
2. ツール:実行レイヤー
それはエージェントの手であり、このレイヤーは思考をアクションに変換します
あなたのエージェントはツールを使用してデータをチェックしたり、メッセージを送信したりすることができます
しかし、ツールがなければ、AIエージェントは単なるテキスト生成システムです
3. メモリ:コンテキストレイヤー
それはあなたのエージェントを時間を通じて一貫性を持たせるものです
これはユーザー設定、テキスト出力のスキーム、スタイルなどである可能性があります
しかし、忘れないでください:メモリをメモ帳の一部として使用しないでください
この戦略はパフォーマンスの低下
原文表示多くの人々は、AIエージェントは単によく書かれたプロンプトに過ぎないと信じています
それを超えて、適切なエージェント部品を選択することは非常に重要です:
> LLM
> ツール
> メモリ
> トリガー
> フィードバックループ
単一のポイントではありません - エージェントは単なる空の話し手です
1. LLM:推論エンジン
この部分は目的、行動方針、実行設計を定義します。
しかし、LLM自体はあなたのシステムに自動アクセスしたり、安定したコンテキストを保持したり、現実世界で行動したりしません
だから「単にGPTを使う」ことはエージェントを構築することと同じではありません
2. ツール:実行レイヤー
それはエージェントの手であり、このレイヤーは思考をアクションに変換します
あなたのエージェントはツールを使用してデータをチェックしたり、メッセージを送信したりすることができます
しかし、ツールがなければ、AIエージェントは単なるテキスト生成システムです
3. メモリ:コンテキストレイヤー
それはあなたのエージェントを時間を通じて一貫性を持たせるものです
これはユーザー設定、テキスト出力のスキーム、スタイルなどである可能性があります
しかし、忘れないでください:メモリをメモ帳の一部として使用しないでください
この戦略はパフォーマンスの低下

- 報酬
- いいね
- コメント
- リポスト
- 共有
AIエージェントの3つの一般的な間違い + 解決策
まず対処しよう -> さもなければ問題が大きくなる
だから事前に修正しよう:
1. 無限ツールコール - リソースが知らないうちに消耗する
エージェントがツールを呼び出し、失敗し、崩壊するまで繰り返し再起動する (ラルフループ)
> 修正:制限とタイムアウトを設定する
2. 途中で忘れる - エージェントが記憶喪失を起こす
エージェントがステップを実行したが前のステップを忘れ、ポイントを見失う
> 修正:Redis/JSONメモリストアと明確なスキーマを使用する
3. エラーが沈黙する - 災害が積み重なる
エージェントがエラーを取得し、無視し、エラーが蓄積し続け、クラッシュする
ユーザーは問題がどこにあるのか全く分からない
> 修正:すべてのステップを監査ログに記録し、ロールバックする
状態 + 制限 + ログ = 成功するエージェント構造
原文表示まず対処しよう -> さもなければ問題が大きくなる
だから事前に修正しよう:
1. 無限ツールコール - リソースが知らないうちに消耗する
エージェントがツールを呼び出し、失敗し、崩壊するまで繰り返し再起動する (ラルフループ)
> 修正:制限とタイムアウトを設定する
2. 途中で忘れる - エージェントが記憶喪失を起こす
エージェントがステップを実行したが前のステップを忘れ、ポイントを見失う
> 修正:Redis/JSONメモリストアと明確なスキーマを使用する
3. エラーが沈黙する - 災害が積み重なる
エージェントがエラーを取得し、無視し、エラーが蓄積し続け、クラッシュする
ユーザーは問題がどこにあるのか全く分からない
> 修正:すべてのステップを監査ログに記録し、ロールバックする
状態 + 制限 + ログ = 成功するエージェント構造
- 報酬
- 2
- コメント
- リポスト
- 共有
OpenClawスキルを3分で作成する方法
スキルは高品質なAIエージェントの重要な要素です
スキルなしでは成り立たず、カスタムスキルはしばしば不可欠です
安全第一:本番運用前に必ずローカルでテストしてください
1. ディレクトリの作成
例 (端末で入力):
| mkdir -p ~/.openclaw/workspace/skills/skill_name
これにより、スキルに必要なすべてのデータが保存されます
2. SKILL·md (LLMへの指示)
重要なポイントは、望むLLMの動作の本質を正しく定式化することです
このファイルはメタデータにYAMLフロントマターを使用し、指示にはMarkdownを使用します
重要:
> 実行可能にし、具体的かつ簡潔に
> 特定のツールを言及
- フロントマターでカスタムツールを定義可能 (任意)
> 何をすべきか、どう反応すべきかを説明
誤った例:
世界に挨拶する
正しい例:
---
name: hello_world
description: 挨拶をするシンプルなスキル。
---
ユーザーが挨拶を求めたとき、echoツールを使って「あなたのカスタムスキルからこんにちは!」と伝える
3. OpenClawをリフレッシュ
エージェントに「スキルをリフレッシュ」またはゲートウェイを手動で再起動させてください
OpenClawは新しいディレク
原文表示スキルは高品質なAIエージェントの重要な要素です
スキルなしでは成り立たず、カスタムスキルはしばしば不可欠です
安全第一:本番運用前に必ずローカルでテストしてください
1. ディレクトリの作成
例 (端末で入力):
| mkdir -p ~/.openclaw/workspace/skills/skill_name
これにより、スキルに必要なすべてのデータが保存されます
2. SKILL·md (LLMへの指示)
重要なポイントは、望むLLMの動作の本質を正しく定式化することです
このファイルはメタデータにYAMLフロントマターを使用し、指示にはMarkdownを使用します
重要:
> 実行可能にし、具体的かつ簡潔に
> 特定のツールを言及
- フロントマターでカスタムツールを定義可能 (任意)
> 何をすべきか、どう反応すべきかを説明
誤った例:
世界に挨拶する
正しい例:
---
name: hello_world
description: 挨拶をするシンプルなスキル。
---
ユーザーが挨拶を求めたとき、echoツールを使って「あなたのカスタムスキルからこんにちは!」と伝える
3. OpenClawをリフレッシュ
エージェントに「スキルをリフレッシュ」またはゲートウェイを手動で再起動させてください
OpenClawは新しいディレク

- 報酬
- 2
- コメント
- リポスト
- 共有
ただ今、MacBookを売ってもう一度下落を待っています
ヘッドフォンとデスクも次です
この市場を生き延びるためのもっと賢い方法はありますか?
原文表示ヘッドフォンとデスクも次です
この市場を生き延びるためのもっと賢い方法はありますか?

- 報酬
- いいね
- コメント
- リポスト
- 共有