โดยสรุป
- Microsoft ได้เปิดตัวสองโหมดที่แตกต่างกันซึ่งจับคู่ GPT และ Claude เพื่อเพิ่มคุณภาพของงานวิจัยด้าน AI
- Critique ให้โมเดลทำงานร่วมกัน ในขณะที่ Council ทำให้โมเดลทำงานแบบขนาน และมีผู้ตัดสินคนที่สามตรวจหาความคลาดเคลื่อน
- เวิร์กโฟลว์แบบสองโมเดลนี้ช่วยแก้ปัญหาการประดิษฐ์ข้อมูล ภาคอ้างอิงที่อ่อนแอ และปัญหาอื่นๆ ที่เกี่ยวข้องกับการวิจัยด้วย AI แบบใช้โมเดลตัวเดียว
AI วิจัยเชิงลึกเป็นหนึ่งในการแข่งขันด้านอาวุธที่ร้อนแรงที่สุดในวงการเทคโนโลยีปีนี้ Google ประกาศเอเจนต์สำหรับงานวิจัยของ Gemini ในเดือนธันวาคม 2024 OpenAI เปิดตัวเอเจนต์สำหรับงานวิจัยของตนเองในเดือนกุมภาพันธ์ 2025 xAI ก็ทำตาม Perplexity ทุ่มสุดตัวเช่นกัน และ Claude ของ Anthropic ก็สร้างฐานผู้ติดตามที่เหนียวแน่นในหมู่ผู้เชี่ยวชาญที่ต้องการคำตอบละเอียดพร้อมแหล่งอ้างอิง โดยเปิดตัวเอเจนต์ในเดือนเมษายนของปีที่แล้ว
ทุกบริษัทต่างพยายามโน้มน้าวคุณว่าโมเดล AI ตัวเดียวของตัวเองคือผู้วิจัยที่ฉลาดที่สุดในห้อง Microsoft เพิ่งพูดว่า: ทำไมต้องเลือกแค่หนึ่ง?
บริษัทประกาศฟีเจอร์ใหม่สองอย่างในวันจันทร์สำหรับเครื่องมือ Copilot’s Researcher — ที่เรียกว่า Critique และ Council — ซึ่งให้ OpenAI’s GPT และ Anthropic’s Claude ทำงานกับงานวิจัยเดียวกันแบบต่อเนื่องกัน ผลลัพธ์จากการทดสอบของ Microsoft เทียบกับเกณฑ์มาตรฐานของอุตสาหกรรมทำคะแนนได้สูงกว่าทุกระบบที่รวมอยู่ในการทดสอบนั้น รวมถึงโมเดลจากบริษัท AI ชั้นนำด้วย
แนะนำ Critique ระบบวิจัยเชิงลึกแบบหลายโมเดลใหม่ใน M365 Copilot
คุณสามารถใช้โมเดลหลายตัวร่วมกันเพื่อสร้างคำตอบและรายงานที่เหมาะสมที่สุด pic.twitter.com/m4RlQmCKzs
— Satya Nadella (@satyanadella) March 30, 2026
“Critique คือระบบวิจัยเชิงลึกแบบหลายโมเดลใหม่ที่ออกแบบมาเพื่อโจทย์วิจัยที่ซับซ้อน มันแยกกระบวนการสร้างจากการประเมิน และใช้การผสมผสานโมเดลจาก Frontier labs รวมถึง Anthropic และ OpenAI” Microsoft อธิบาย “โมเดลหนึ่งเป็นผู้นำในช่วงการสร้าง วางแผนงาน ทำซ้ำผ่านการดึงข้อมูล และจัดทำร่างเริ่มต้น ขณะที่โมเดลที่สองโฟกัสที่การทบทวนและการปรับปรุง ทำหน้าที่เป็นผู้ตรวจทานผู้เชี่ยวชาญก่อนที่จะมีการผลิตรายงานฉบับสุดท้าย”
ปัญหาพื้นฐานที่ Critique ออกแบบมาเพื่อแก้ก็คือ: เครื่องมือวิจัยด้าน AI ทุกวันนี้ทำงานในแบบเดียวกัน คุณถามคำถาม โมเดลหนึ่งวางแผนการค้นหา ค้นแหล่งข้อมูล เขียนรายงาน แล้วส่งกลับให้คุณ โมเดลตัวเดียวนั้นทำทุกอย่างโดยไม่มีใครมาตรวจทานงานของมัน
สิ่งนี้อาจนำไปสู่การที่ข้อมูลที่ “หลุด” แบบการประดิษฐ์ข้อเท็จจริงบางส่วนแทรกเข้ามา ข้อผิดพลาดในภาคอ้างอิง ข้ออ้างที่เป็นเท็จหรือไม่แม่นยำ ฯลฯ
Critique ทำลายเวิร์กโฟลว์นั้นให้แบ่งเป็นสองส่วน GPT รับหน้าที่ในเฟสแรก — วางแผนการวิจัย ดึงแหล่งข้อมูล และเขียนร่างเริ่มต้น จากนั้น Claude จะเข้ามาทำหน้าที่เป็นบรรณาธิการที่เข้มงวด โดยทบทวนรายงานเพื่อความถูกต้องของข้อเท็จจริง คุณภาพของคำอ้างอิง และคำตอบนั้นตอบได้จริงหรือไม่ว่าตรงกับสิ่งที่ถูกถาม หลังจากการทบทวนนี้เท่านั้น รายงานฉบับสุดท้ายจึงไปถึงผู้ใช้งาน Microsoft ระบุว่า บทบาทเหล่านี้สามารถทำงานย้อนทิศทางกันได้ในที่สุดเช่นกัน โดยให้ Claude เป็นฝ่ายร่าง และ GPT เป็นฝ่ายตรวจวิจารณ์ แต่ตอนนี้ GPT จะไปก่อน
ในเกณฑ์มาตรฐาน DRACO — แบบทดสอบมาตรฐานที่ครอบคลุมงานวิจัยเชิงซับซ้อน 100 งานใน 10 สาขา รวมถึงการแพทย์ กฎหมาย และเทคโนโลยี — Copilot พร้อม Critique ได้ 57.4 คะแนน ขณะที่ Anthropic’s Claude Opus ได้ 42.7 เพียงลำพัง ระบบแบบรวมของ Microsoft ชนะผลลัพธ์อันดับถัดไปที่ดีที่สุดไปเกือบ 14%
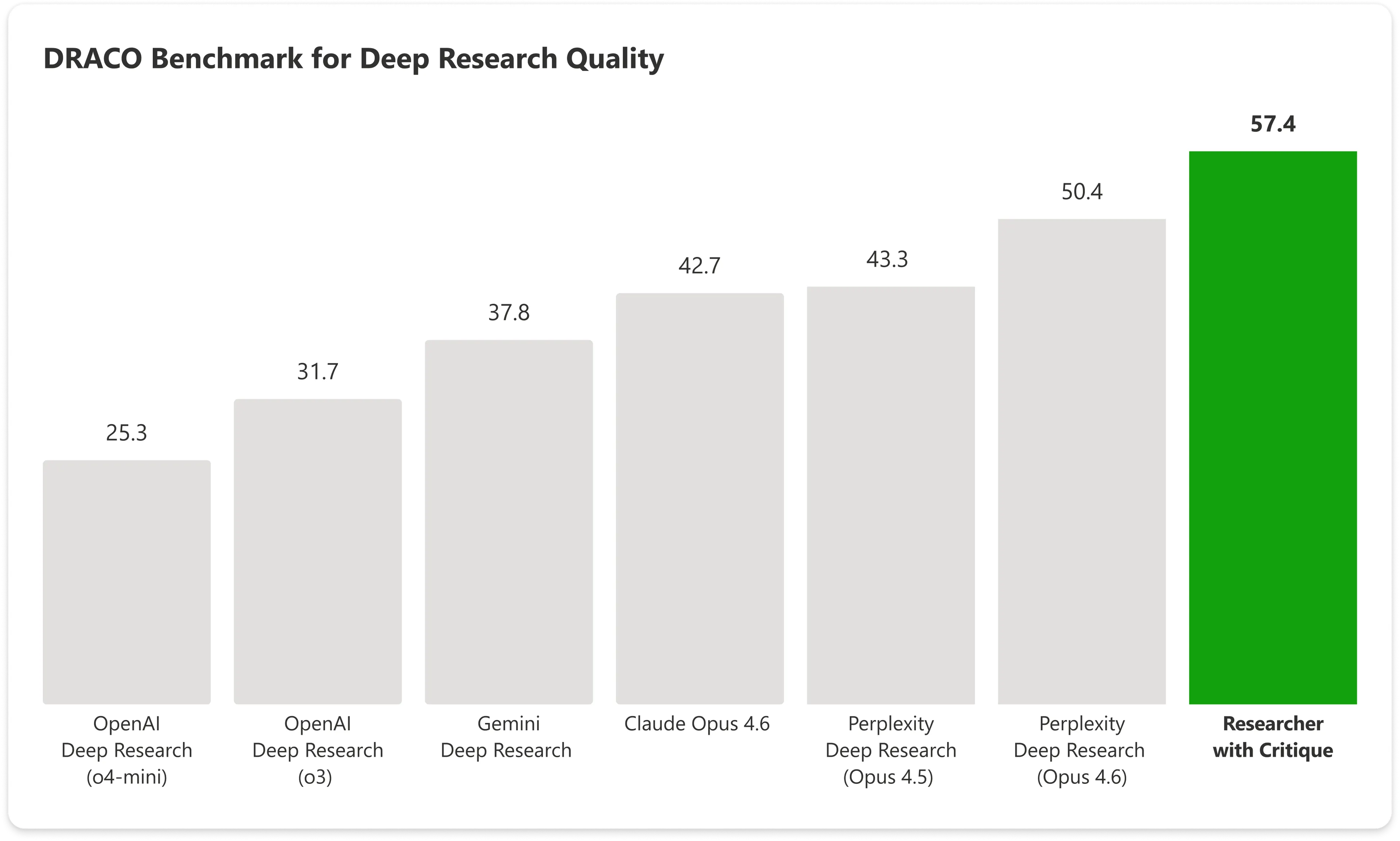
ภาพ: Microsoft
การเพิ่มขึ้นที่เด่นที่สุดเกิดขึ้นในขอบเขตของการวิเคราะห์และคุณภาพการนำเสนอ โดยความถูกต้องของข้อเท็จจริงก็มีการปรับปรุงอย่างมีนัยสำคัญเช่นกัน
ฟีเจอร์ที่สองคือ Council ใช้วิธีที่แตกต่างกับปัญหาชุดเดียวกัน แทนที่จะให้โมเดลตัวหนึ่งมาตรวจงานของอีกตัว Council จะรัน GPT และ Claude พร้อมกัน และวางรายงานฉบับเต็มของทั้งสองขนานกันไว้ จากนั้นโมเดล “ผู้ตัดสิน” คนที่สามจะอ่านทั้งสองรายงานและเขียนสรุปอธิบายว่า AI ทั้งสองเห็นพ้องกันตรงไหน แตกต่างกันตรงไหน และแต่ละตัวจับได้มุมเฉพาะที่อีกตัวพลาดไปอย่างไร การเปรียบเทียบเครื่องมือวิจัยด้าน AI แบบใช้มือเป็นสิ่งที่ผู้ใช้งานต้องทำเองจนถึงตอนนี้
ใน Critique โมเดลต่างๆ ทำงานร่วมกันกัน โดยแท้ ขณะที่ใน Council โมเดล แข่งขัน กันเอง
Critique เป็นประสบการณ์เริ่มต้นใน Researcher ขณะที่ Council ต้องให้คุณเลือก “Model Council” จากตัวเลือกเพื่อเปิดโหมดแสดงแบบเคียงข้างกัน ทั้งสองฟีเจอร์มีให้ผู้ใช้ที่ลงทะเบียนในโปรแกรม Frontier ของ Microsoft ซึ่งเป็นช่องทางสิทธิ์ทดลองใช้สำหรับความสามารถใหม่ล่าสุดของ Copilot ในตอนนี้ ใบอนุญาต Microsoft 365 Copilot ($30/user/month) จำเป็นต้องใช้ แต่ผู้ใช้ก็ต้องลงทะเบียน Frontier เพื่อเข้าถึงเช่นกัน
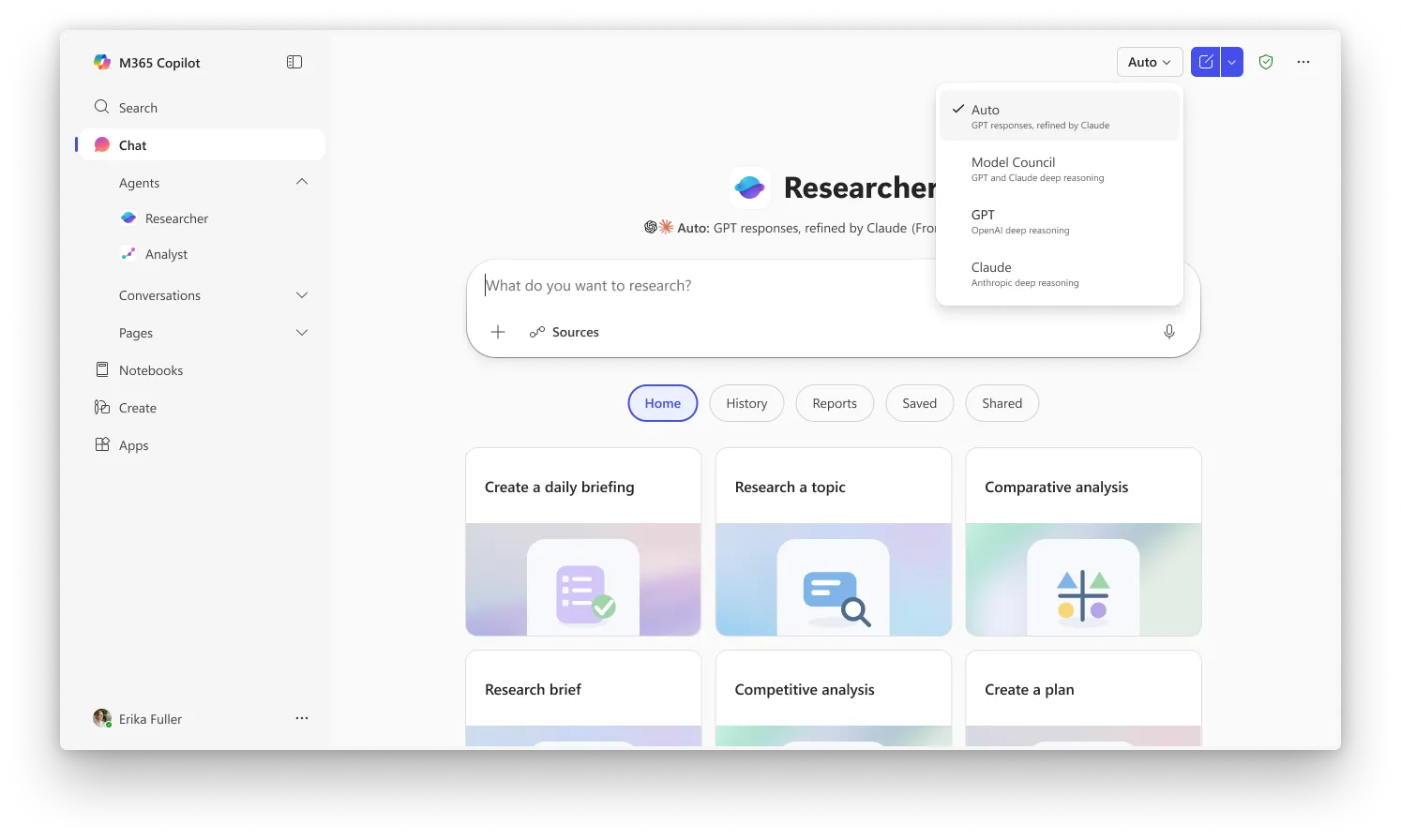
ภาพ: Microsoft
OpenAI และ Microsoft มีพาร์ทเนอร์ชิประดับหลายพันล้านดอลลาร์ แต่เดิมพันของ Microsoft คือ ไม่มีโมเดลตัวใดที่จะอยู่อันดับหนึ่งได้ตลอดไป และคุณค่าที่แท้จริงอยู่ที่ชั้นการประสานงานที่ส่งงานไปยังชุดโมเดลที่ทำงานได้ดีที่สุดตามแต่ละสถานการณ์
